
Googleが公開した、MLOps実践のためのホワイトペーパー
GoogleがMLOps実践のためのホワイトペーパーを公開しています。
Practitioners Guide to Machine Learning Operations (MLOps)
2021年5月に公開されたものですが、2024年現在に読んでも色褪せない内容だったので、各章の要点をまとめました。
TL;DR
- Googleが2021年5月に公開したMLOpsの実践のためのホワイトペーパー
- MLOpsライフサイクルの全体像・コア機能を解説
- MLOpsのコアプロセスの詳細を解説
- コアプロセス: ML開発、学習の運用化、継続的学習、モデルデプロイ、推論サービス、継続的監視、データ・モデル管理
目次
- Googleが公開した、MLOps実践のためのホワイトペーパー
- TL;DR
- 目次
- 1. Executive summary
- 2. Overview of MLOps lifecycle and core capabilities
- 3. Deep dive of MLOps processes
- 4. Putting it all together
以下、各章の要点です
1. Executive summary
本書はGoogle Cloudが公開してる AI Adoption Frameworkの中から、スケールと自動化を詳しく掘り下げた内容。
本ドキュメントはコアコンセプトと技術的機能を定義するMLOpsフレームワークを解説。
2部構成
- MLOpsのライフサイクルの概要。全ての読者が対象。
- MLOpsのプロセスとスキルの詳細。MLOpsの具体的なタスクを知りたい読者が対象。
2. Overview of MLOps lifecycle and core capabilities
様々な企業に対しての調査結果から、機械学習モデルが本番環境にデプロイされずに終わる、またはデプロイされても環境変化に追従できず失敗する事例が数多く見られる。
この要因を考えた研究に共通してることは、MLシステムをDataOpsやDevOpsのようなML以外の技術から分離したアドホックな方法で構築できないからであるということ。
組織にはMLエンジニアリングによって実現できる、自動化されたスムーズなMLプロセスが必要。
MLOpsはMLエンジニアリングのための方法論であり、MLシステムの開発と運用を統合する。
MLOpsの実践による利点
- 開発サイクルの短縮・市場投入までの時間短縮
- チーム間の協力の向上
- MLシステムの信頼性・パフォーマンス・拡張性・セキュリティの向上
- 運用・ガバナンスプロセスの効率化
- MLプロジェクトの費用対効果の改善
2.1 Building an ML-enabled system
MLを活用したシステムの構築は、データエンジニアリング・MLエンジニアリング・アプリケーションエンジニアリングを組み合わせた多面的な取り組み。
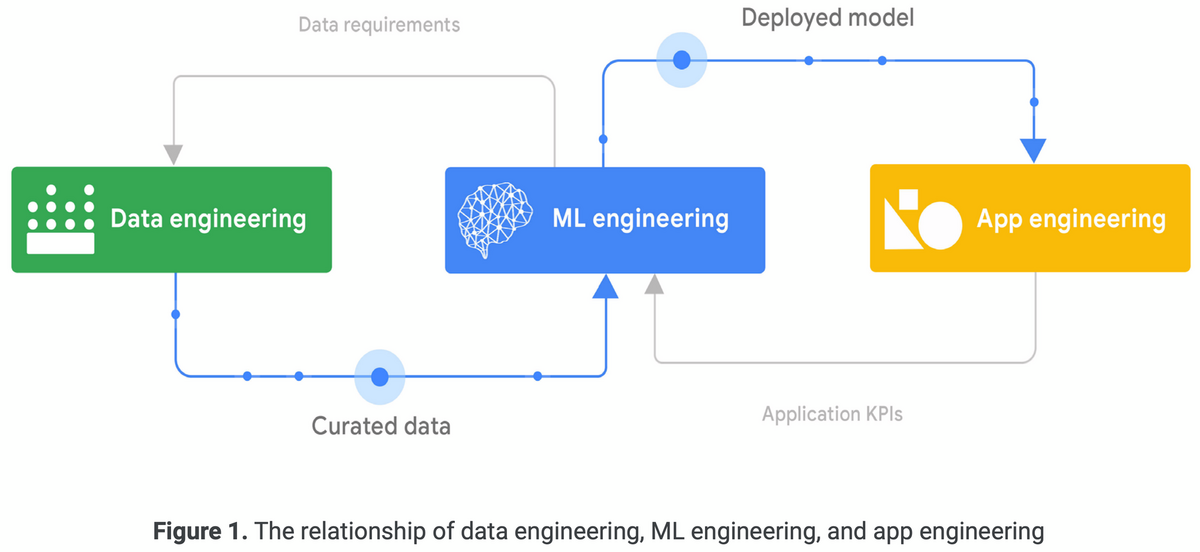
2.2 The MLOps lifecycle
MLOpsのライフサイクルは、7つの統合された反復プロセスが含まれる。
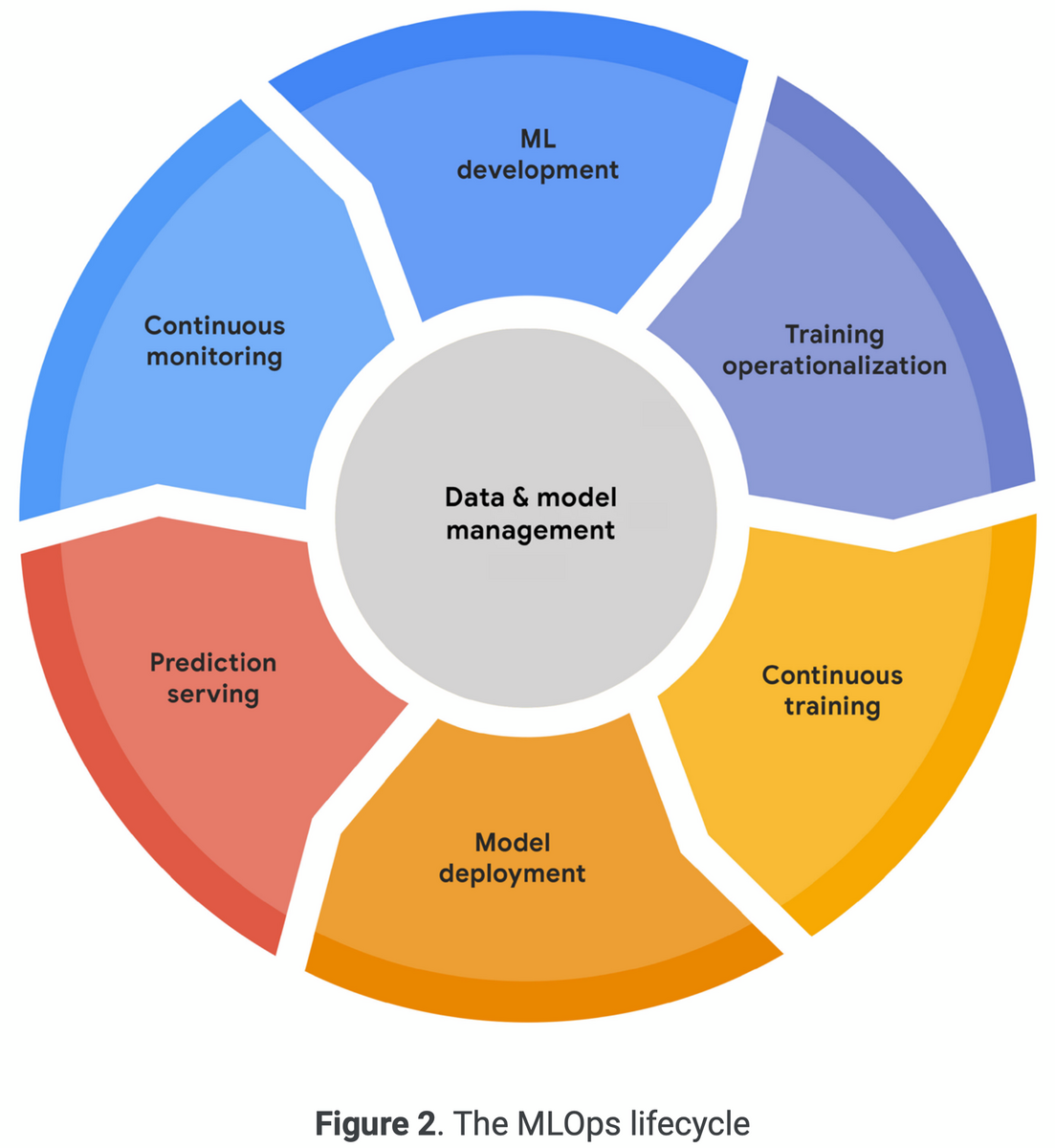
- モデル開発
- 汎用性が高く再現性のあるモデル学習パイプラインの実験と開発
- モデル学習の運用化
- 再利用可能で信頼性の高い学習パイプラインのパッケージ化・テスト・デプロイのプロセスを自動化
- 継続的学習
- 新しいデータやコードの変更・スケジュールに従って学習パイプラインを実行
- モデルデプロイ
- オンライン実験と本番サービングのためにモデルをパッケージ化・テスト・デプロイ
- 推論サービス
- 本番環境のモデルを推論のためにデプロイ
- 継続的監視
- デプロイされたモデルの効果と効率を監視
- データ・モデル管理
2.3 MLOps: An end-to-end workflow
MLOpsプロセスの典型的なフロー。
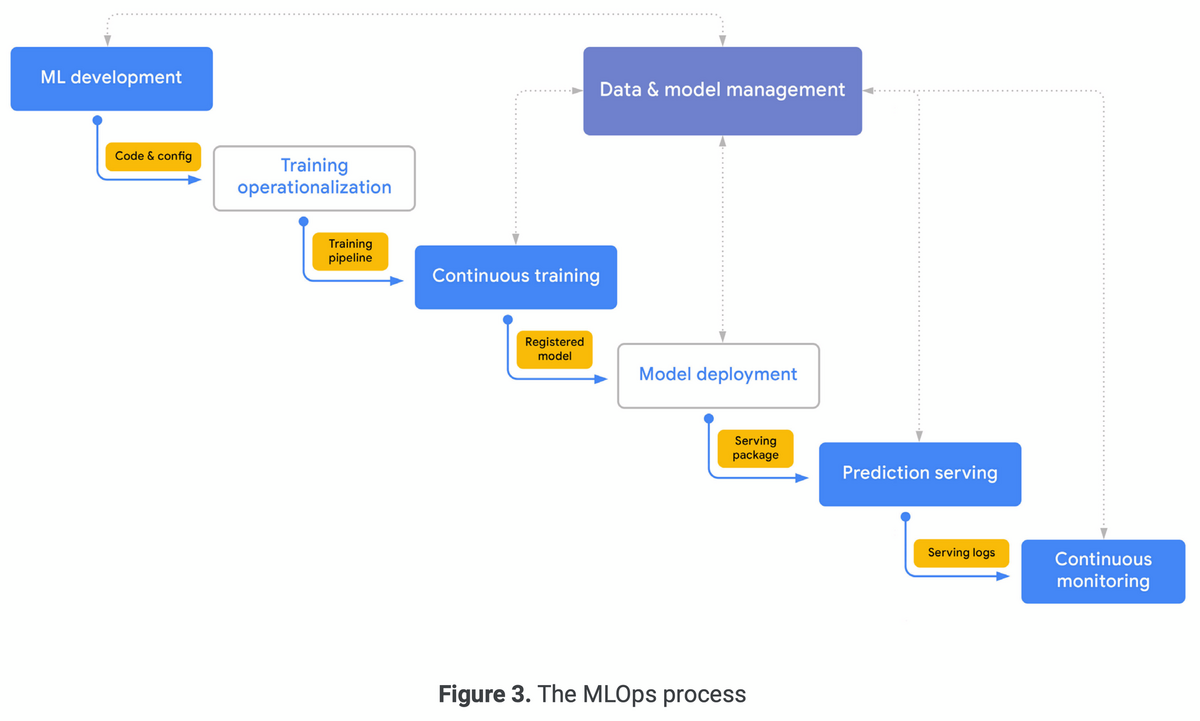
2.4 MLOps capabilities
MLOpsプロセスを効果的に実装するために、組織は一連のコア技術機能を確立する必要がある。
スケーラブルでセキュアなインフラストラクチャ・標準化された構成管理とCI/CD環境が、ITシステムを構築するための基盤機能。
この上にMLOpsの機能である、実験・データ処理・モデルトレーニング・モデル評価・モデルサービング・オンライン実験・モデル監視・MLパイプライン・モデルレジストリがある。
横断的な能力として、MLメタデータ・アーティファクトレポジトリと、データセット・特徴量レポジトリがある。
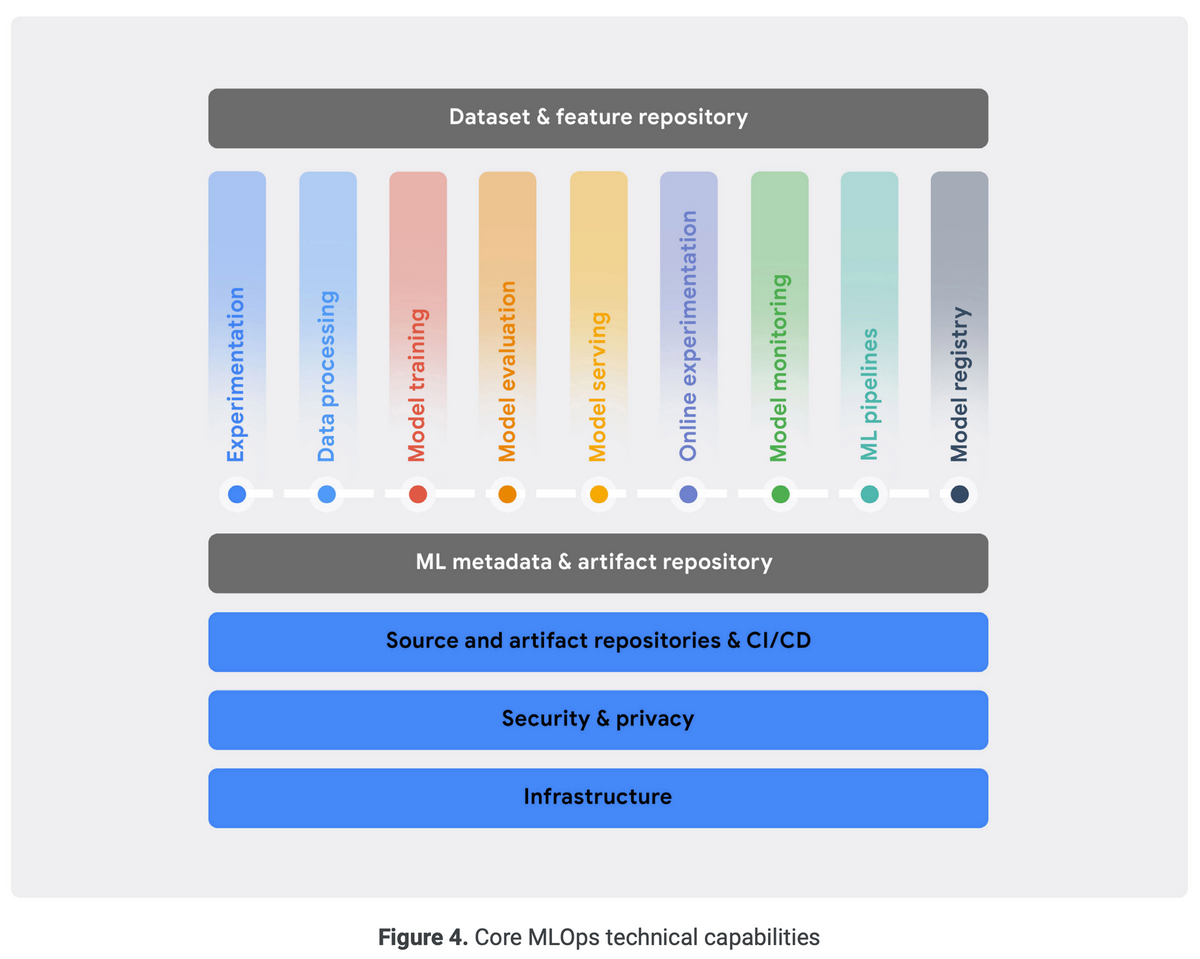
2.4.1 Experimentation
主要機能
- バージョン管理ツールと統合されたノートブック環境を提供
- 再現性と比較のために、データ・ハイパーパラメータ・評価指標の情報を含んだ実験の追跡
- データ・モデルの分析と可視化
- データセットの探索、実験の確認、実装レビューをサポート
- プラットフォームにある他のデータ・機械学習サービスとの統合
2.4.2 Data processing
主要機能
- 短時間の実験のためのインタラクティブな実行、長時間の本番環境でのジョブ実行に対応
- 様々なデータソースやサービスとの接続、様々なデータ構造やフォーマットに対するエンコーダとデコーダを提供
- 構造化・非構造化データに対して、豊富で効率的なデータ変換と特徴エンジニアリングを提供
- ML学習と推論サービング処理のために、スケーラブルなバッチ・ストリームデータ処理に対応
2.4.3 Model training
主要機能
- 一般的なMLフレームワーク・カスタムランタイム環境に対応
- 複数GPUと複数ワーカーに対する、異なる戦略の大規模な分散学習
- MLアクセラレータのオンデマンド利用
- スケールする効率的なハイパーパラメータチューニングとターゲット最適化に対応
- 理想的には、特徴量選択・特徴量エンジニアリング・モデルアーキテクチャ探索と選択の自動化を含む、組み込みのAutoML機能を提供
2.4.4 Model evaluation
主要機能
- 大規模な評価データセットでモデルのバッチ評価を実行
- 様々な分割データに対して事前定義 or カスタム評価指標を計算
- 異なる学習環境の学習済みモデルの予測パフォーマンスを追跡
- 異なるモデル同士の精度を視覚化・比較
- 何かの分析やバイアスや公平性の問題を特定するツールを提供
- Explainable AI技術を使用したモデルの振る舞いの解釈
2.4.5 Model serving
主要機能
- 低レイテンシーのリアルタイム推論と高スループットのバッチ推論に対応
- 一般的なMLサービングフレームワークとカスタムランタイム環境の組み込みサポートを提供
- 結果集約前に複数モデルを階層的に呼び出す合成予測ルーチンと、事前・事後処理ルーチンに対応
- ワークロードのスパイクに対応し、コストとレイテンシーのバランスを保つためにオートスケーリングする、ML推論アクセラレータの効率的な使用
- 特徴量重要度などの技術を使用したモデル解釈性を提供
- 分析のための予測リクエスト・レスポンスのロギング
2.4.6 Online experimentation
主要機能
2.4.7 Model monitoring
主要機能
- レイテンシやサービングリソース利用率など、モデル効率の指標を測定
- スキーマの異常、データ・コンセプトのシフト・ドリフトなどの、データ歪みを検出
- デプロイされたモデルのパフォーマンスを継続的に評価するために、モデル評価機能と監視を統合
2.4.8 ML pipelines
主要機能
- オンデマンド、スケジューリング、特定イベントに応じてパイプラインをトリガー
- ML開発中のデバッグのために、ローカルでの対話型実行に対応
- MLメタデータ追跡機能と統合し、パイプラインの実行パラメータを保持、アーティファクトを生成
- 一般的なMLタスク向けの組み込みコンポーネントとカスタムコンポーネントを提供
- ローカルマシンやスケーラブルなクラウドプラットフォームの異なる環境で実行
- パイプラインの設計および構築のためのGUIツールを提供
2.4.9 Model registry
主要機能
- 学習済み、デプロイされたMLモデルの登録、整理、追跡、バージョン管理
- デプロイ可能性のためにモデルメタデータとランタイム依存関係を保持
- モデルのドキュメントとレポーティングを維持
- モデル評価およびデプロイ機能を統合し、モデルのオンライン・オフライン評価指標を追跡
- モデルの起動プロセス(レビュー・承認・リリース・ロールバック)の管理
2.4.10 Dataset and feature repository
主要機能
- データ資産の共有性・発見性・再利用性・バージョニング
- イベントストリーミングやオンライン予測ワークロードに対する、リアルタイムデータ取り込みと低レイテンシーサービング
- ETLプロセスやモデル学習、モデル評価ワークロードに対する、高スループットのバッチ取り込みとサービング
- 特定時点のクエリ用に対する特徴のバージョニング
- テーブル、画像、テキストなど、さまざまなデータ形式をサポート
2.4.11 ML metadata and artifact tracking
主要機能
- MLアーティファクトの追跡可能性と系統的追跡
- 実験とパイプラインパラメータ設定の共有と追跡
- MLアーティファクトの保存、アクセス、調査、可視化、ダウンロード、アーカイブ
- すべての他のMLOps機能と統合
3. Deep dive of MLOps processes
3.1 ML development
実験プロセスはML開発の中心的活動であり、データサイエンティストがデータ準備とモデル学習のためのアイディアを素早く試すことができる。
実験の目的は手元のMLユースケースに対して効果的なプロトタイプモデルを作ること。
データサイエンティストはML学習手順をエンドツーエンドのパイプラインを実装することで形式化する必要がある。
以下はML開発のプロセスの全体像を表した図。
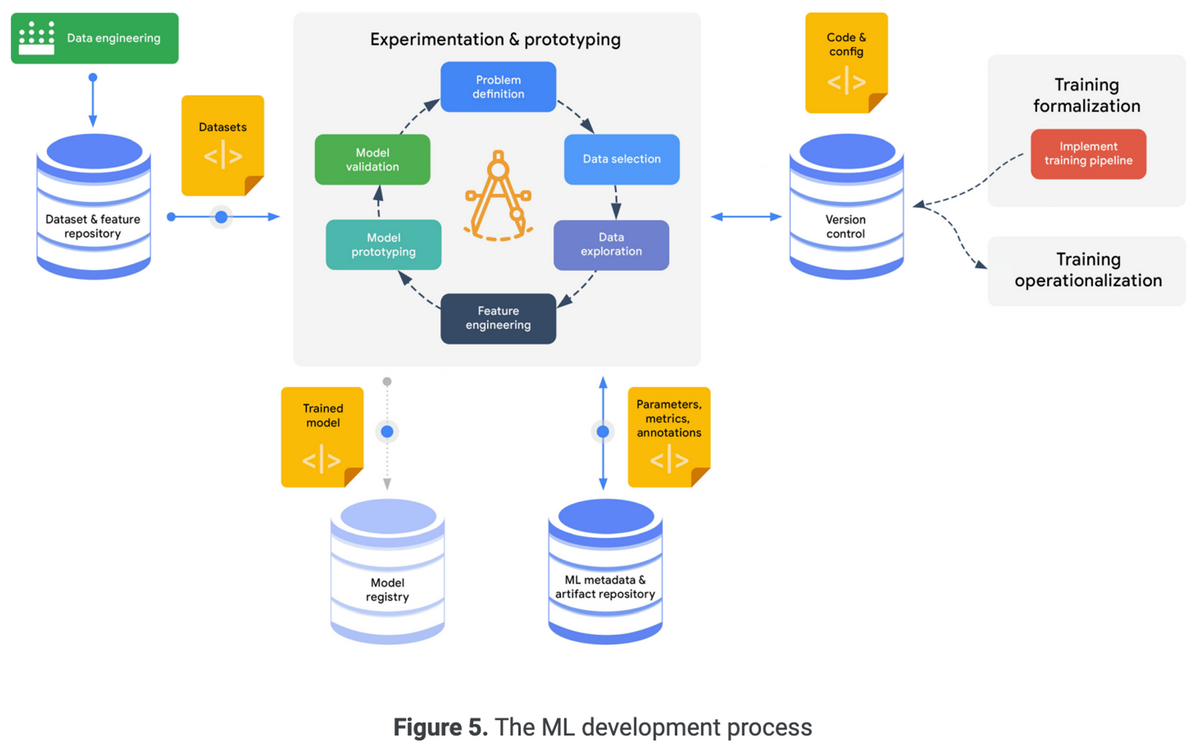
実験プロセスの成功要因は実験の追跡、再現性、協調にある。
実験を再現するためにデータサイエンティストが以下の実験設定を追跡する必要がある。
- バージョン管理システム内の学習コードのバージョン
- モデルアーキテクチャと事前学習済みモジュール
- ハイパーパラメータ
- 学習・検証・テストデータの分割に関する情報
- モデル評価指標と検証手順
MLモデルを定期的に再学習する場合、継続的学習パイプラインの実装が本番環境にデプロイされる。
新しい特徴やデータセットはデータエンジニアリングパイプラインに統合される。
3.2 Training operationalization
学習の運用化は、繰り返し可能なML学習パイプラインを開発・テストし、実行環境にデプロイするプロセス。
MLOpsでは、MLエンジニアは設定を使用してMLパイプラインを展開できる必要がある。
通常、パイプラインは本番環境にリリースされる前に、一連のテスト、検証環境を経由する。
コードファースト技術を使用する場合、MLエンジニアは標準のCI/CDプロセスとツールを使用してパイプラインをデプロイできる。
以下は学習パイプラインのデプロイを表した図
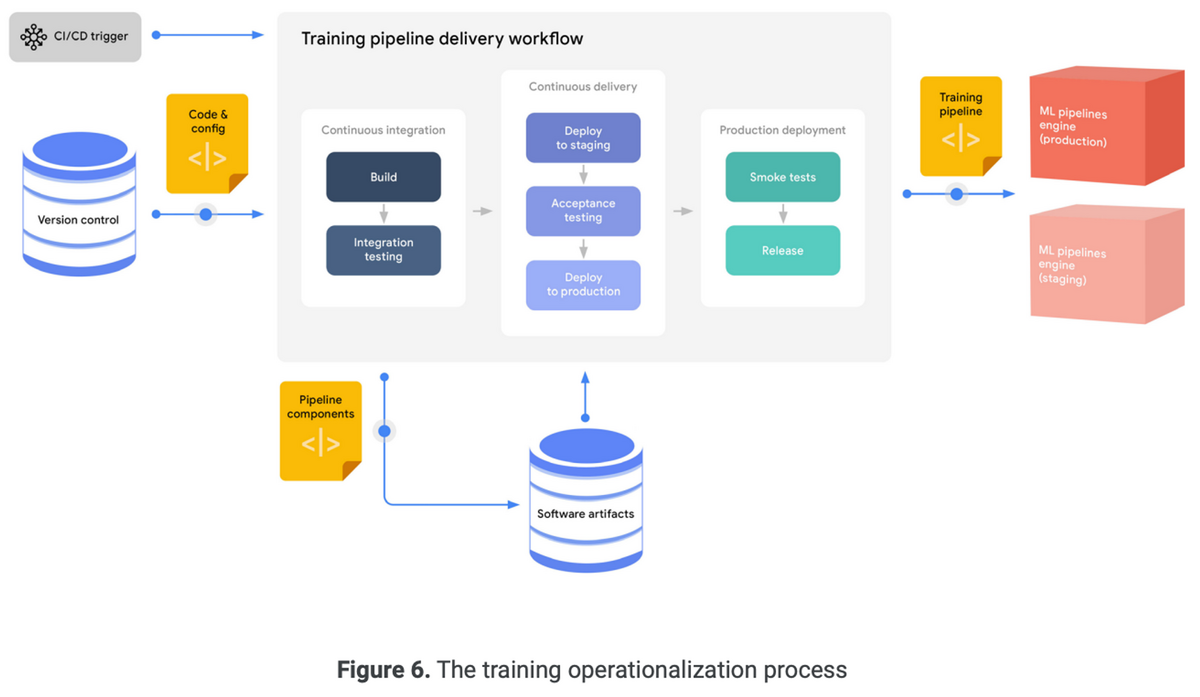
3.3 Continuous training
継続的学習プロセスは、学習パイプラインの実行をオーケストレーションおよび自動化すること。モデルの再学習の頻度は、MLのユースケースや再学習のビジネス価値およびコストに依存する。
学習パイプラインのトリガー方法
- スケジュールされた実行
- イベント駆動
- 手動実行
以下は典型的なML学習パイプラインの流れを表した図
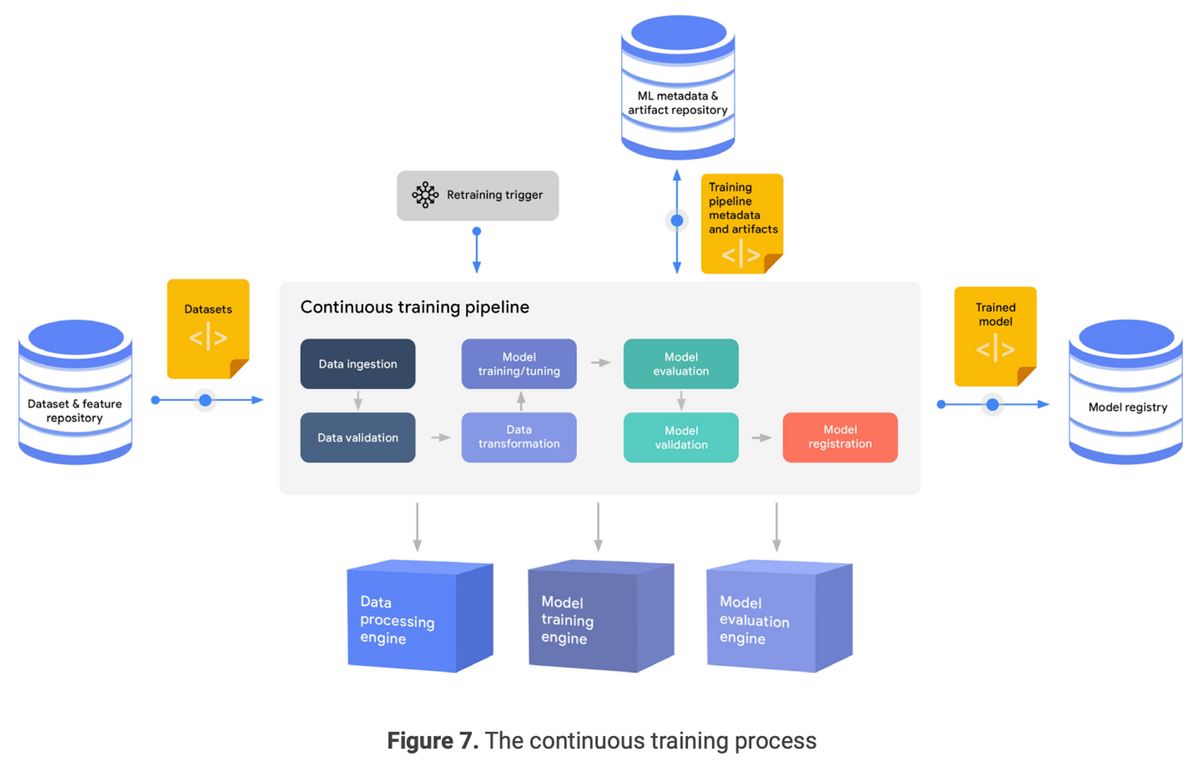
以下のワークフローが含まれる
- データ取り込み
- データ検証
- データ変換
- モデル学習
- モデル評価
- モデル検証
- モデル登録
継続的学習の重要な側面はデータとモデルが追跡可能であること。
完全なパイプラインをすべての組織で構築するのは実用的ではない場合がある。
3.4 Model deployment
モデルデプロイプロセスでは、モデルがパッケージ化・テストされ、目的のサービング環境にデプロイされる。
ノーコードやローコードのソリューションを使用する場合、モデルデプロイプロセスは簡素化・抽象化される。モデルレジストリ内のモデルエントリを指定すると自動的にデプロイされる。
デプロイに細かな制御が必要な場合、複雑なCI/CDルーチンが必要。ソースコードからモデルを取得し、テスト、ビルド、検証、デプロイを行う。
以下はCI/CDのプロセスを表した図
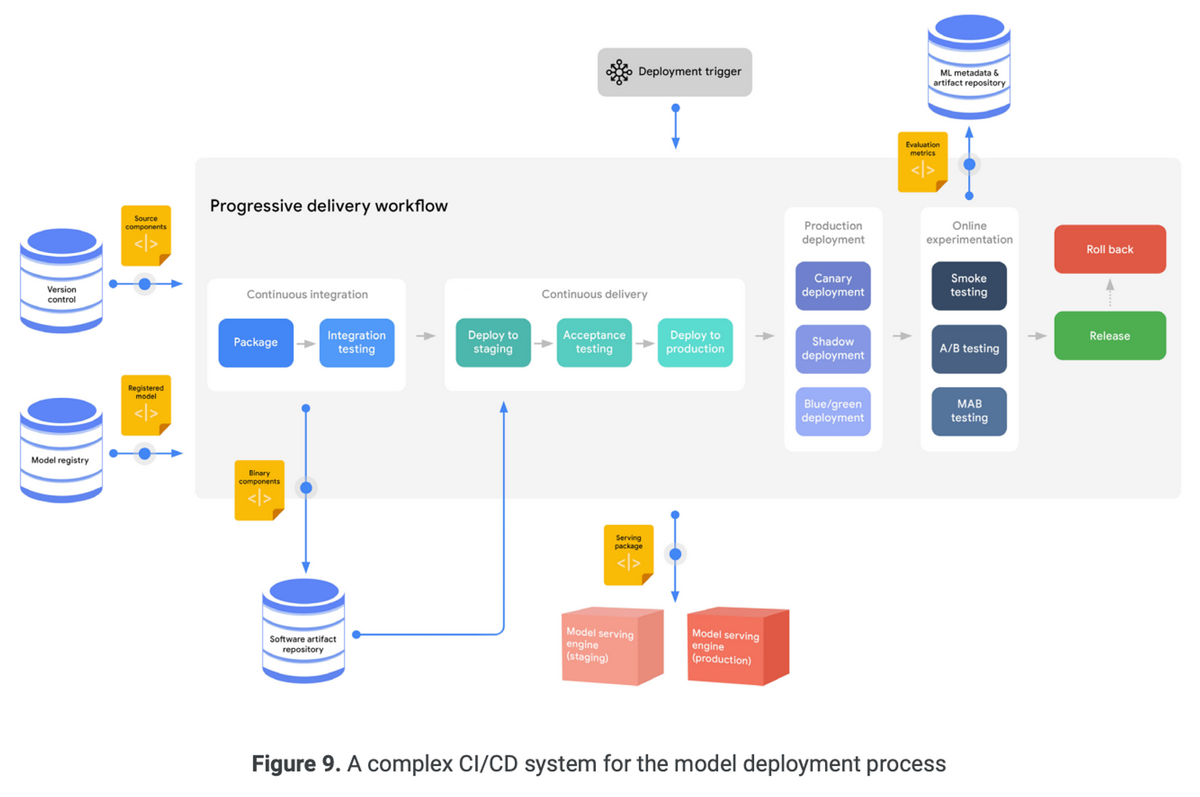
CIステージでは、モデルのインターフェース、互換性、レイテンシなどがテストされる。
CDステージでは、カナリアデプロイやシャドウデプロイなどの方法を用いて、進行的な配信が行われる。
オンライン実験は特にMLの文脈で重要。A/Bテストや多腕バンディットテストなどの抱負を用いて、新しいモデルの本番環境での効果をテストする。
3.5 Prediction serving
予測サービングプロセスは、モデルがサービング環境にデプロイされた後、予測リクエストを受け付け、予測結果と共にレスポンスを提供する。
予測サービングの要素を表した図
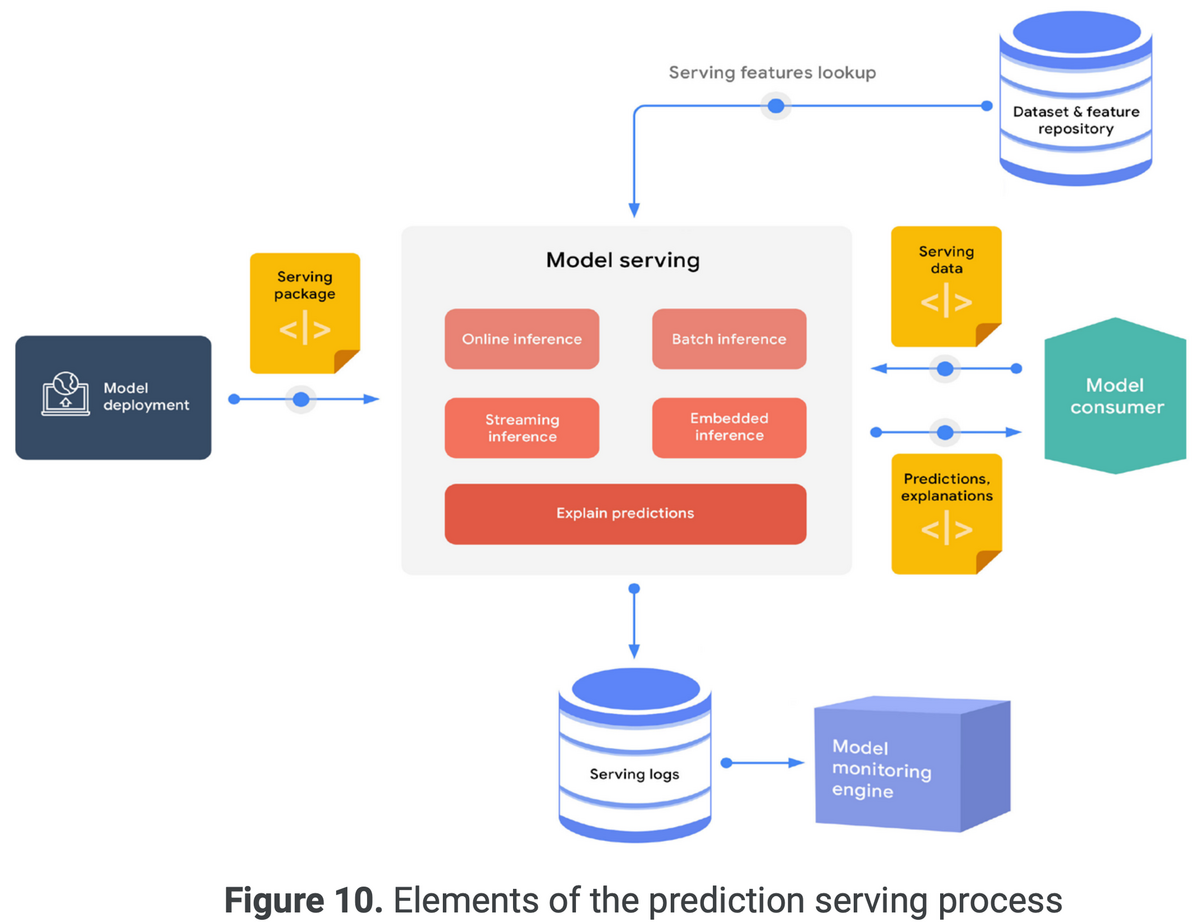
予測値を以下の形式で提供する
- オンライン推論
- ストリーミング推論
- バッチ推論
- エッジデバイス上での推論
サービングエンジンはリクエストに関する特徴量を必要とする場合、特徴量レポジトリから特徴量を取得しモデルへ入力する。
MLシステムの信頼性の一部は、モデルの解釈と予測に対する説明が可能であること。特徴量寄与度を用いて予測の根拠を明らかにする。
推論ログや他のメトリクスは、継続的な監視と分析のために保存する。
3.6 Continuous monitoring
継続的監視は、本番環境のモデルの有効性と効率を監視するプロセスで。MLOpsの重要な領域。
典型的な継続監視プロセスの手順
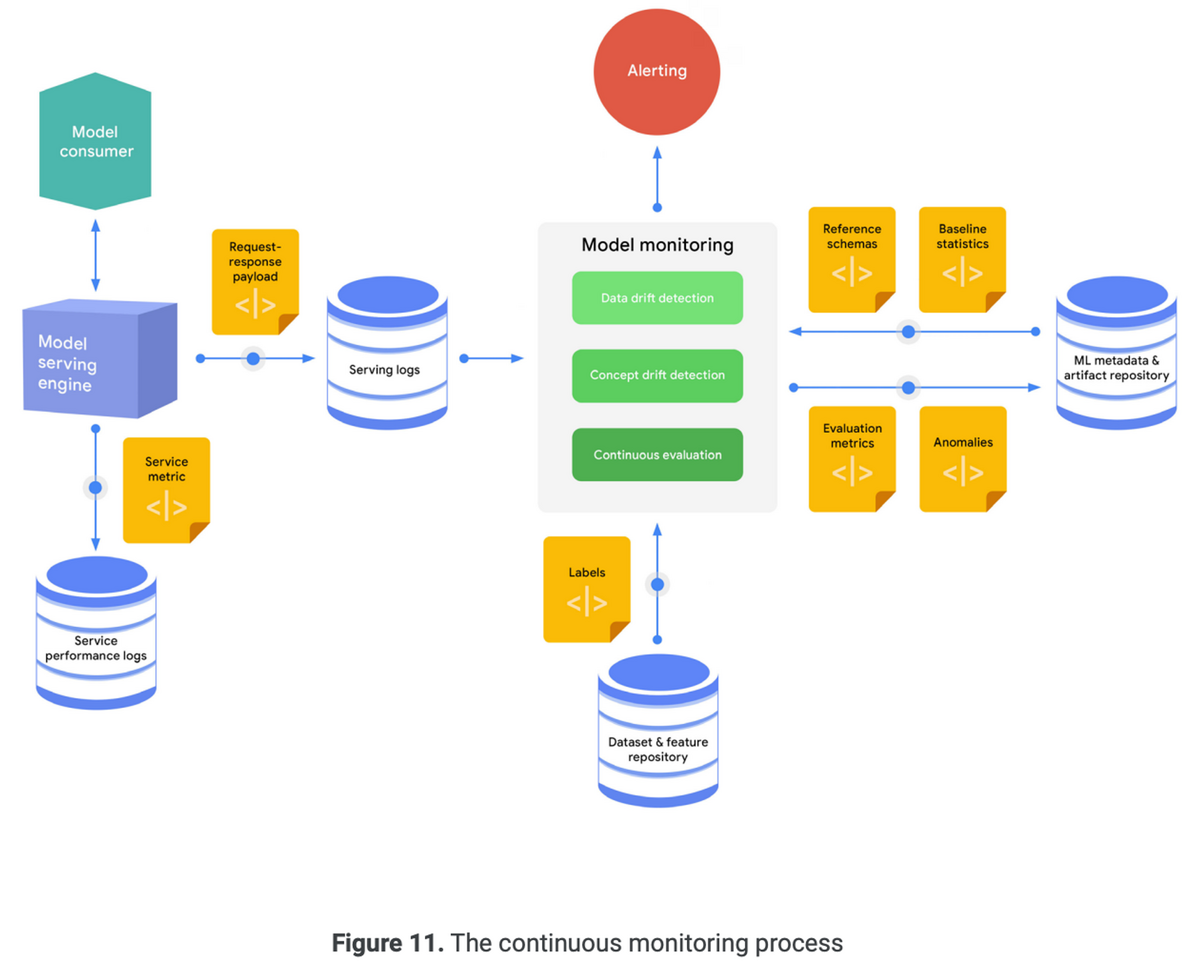
- リクエスト・レスポンスのペイロードのサンプルをキャプチャ
- 推論ログのスキーマ生成・統計計算
- 推論ログ統計とベースライン統計の比較から分布のズレを特定
- グラウンドトゥルースを利用した予測の評価
- 異常時のアラート
効果的なパフォーマンス監視は、モデルの劣化を検出することを目指す。モデルの劣化は、データドリフト・コンセプトドリフトで定義される。
モデルのサービング効率の監視は、リソース利用率、レイテンシ、スループット、エラー率などの指標に注目する。
3.7 Data and model management
3.7.1 Dataset and feature management
データサイエンスと機械学習の主要な課題の1つは、モデル学習用の高品質なデータを作成、維持、再利用すること。
データサイエンティストは、探索的データ分析、データ準備、データ変換に多くの時間を費やす。
予測サービングの一般的な課題は、トレーニングサービングスキューと呼ばれる、推論データと学習データの間の不一致。
データセット・特徴の管理は、このような問題を軽減するために、データセット・特徴の統一されたリポジトリを提供する。
以下はデータセット・特徴のリポジトリを使用して、複数用途にエンティティを提供する図
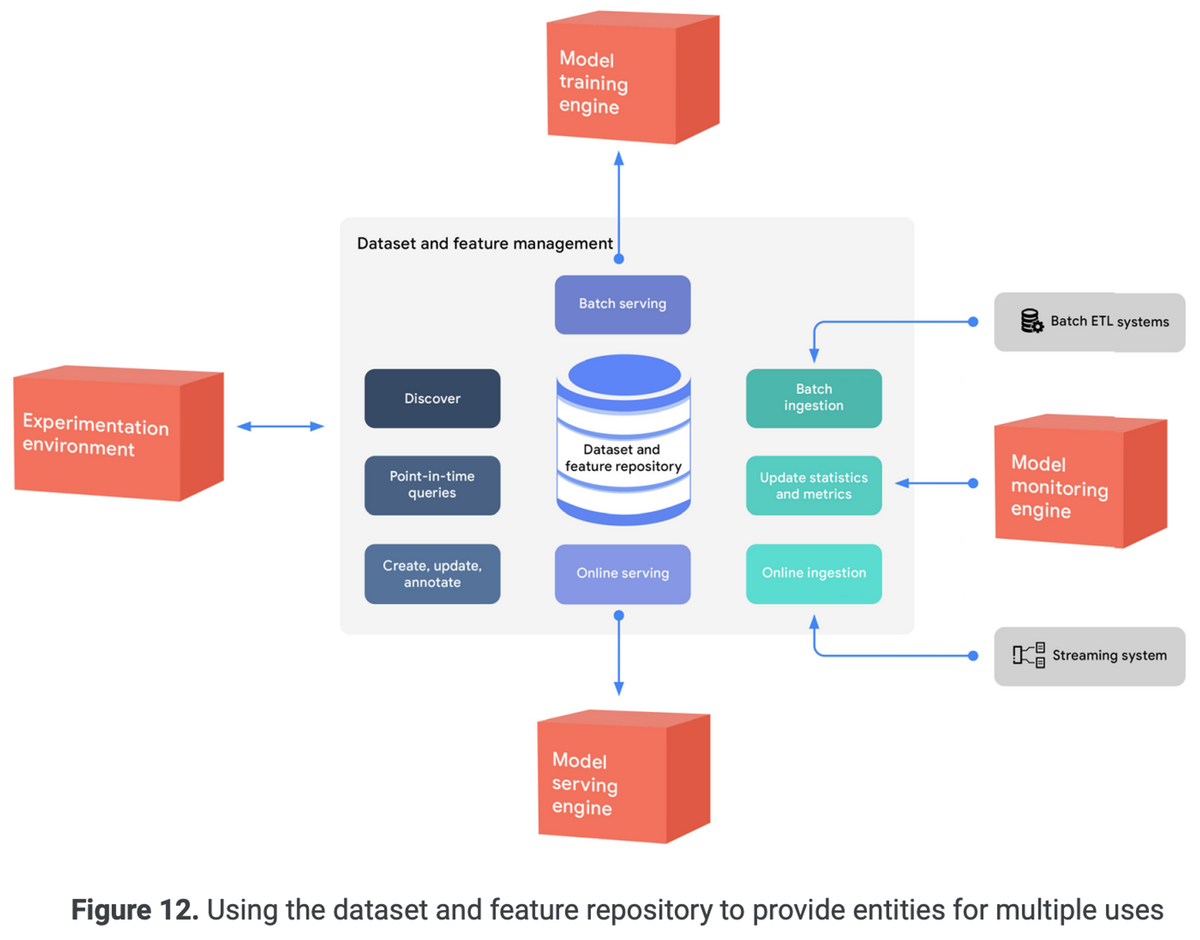
3.7.1.1 Feature management
特徴量は標準的なビジネスルールに基づいて整理された、ビジネスエンティティの属性。
データエンティティを中央管理レポジトリで管理することで、学習とサービングのためにエンティティの定義、保存、アクセスを標準化できる。
特徴量レポジトリで以下のことが行えるようになる
- 利用可能な特徴を再利用
- 特徴量の定義を確立
- トレーニングサービングスキューの回避
- 最新の特徴値を取得
- 新しいエンティティと特徴を定義し、共有する
- チーム間協力の改善
バッチETLシステムでは、学習タスクのために特徴をバッチとして取得できる。
オンラインサービングでは、サービングエンジンが要求されたエンティティに関連する特徴値を取得できる。
3.7.1.2 Dataset management
データセット管理は、以下の点で役立つ
- 異なる環境でデータセットを作成
- チーム内で単一のデータセット定義と実現を維持
- 同じデータセットとタスクに共同作業しているチームメンバーにとって役立つメタデータと注釈を維持する。
- 再現性と系列追跡を提供
3.7.2 Model management
モデル管理は組織がリスクを管理し、MLモデルを責任を持って実装し、規制を遵守するためのコントロール。
モデル管理は以下の点で役立つ
3.7.2.1 ML metadata tracking
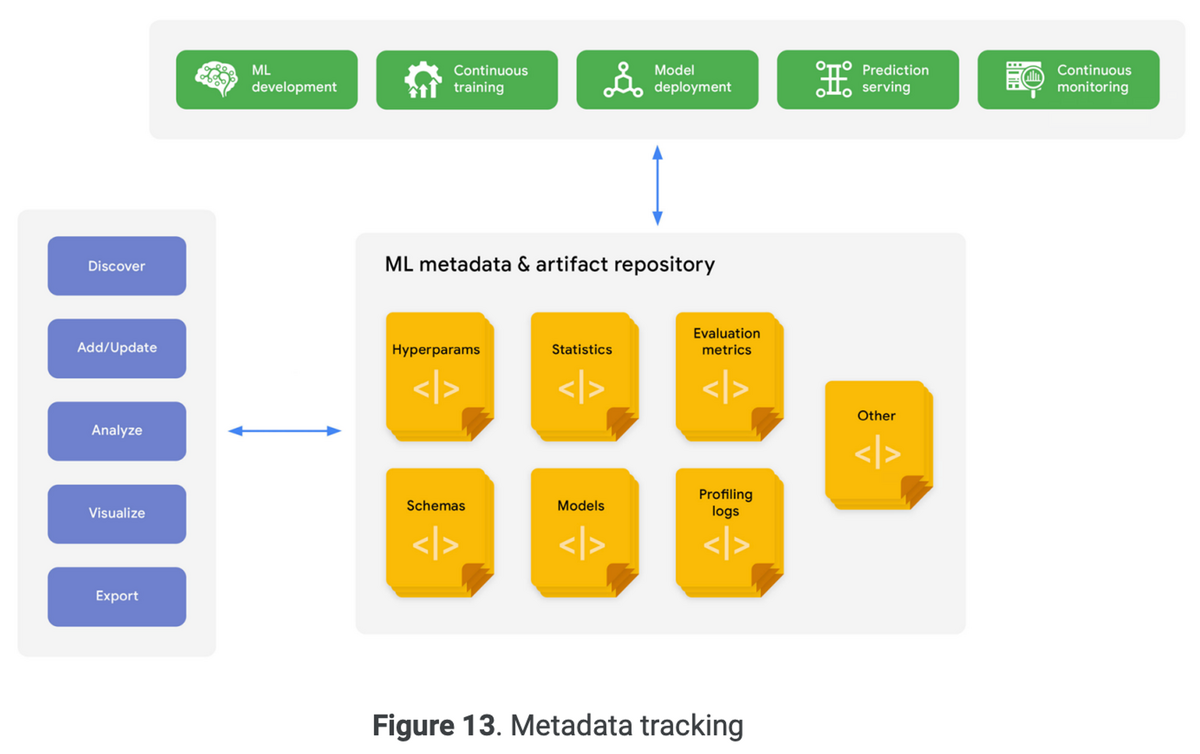
MLメタデータトラッキングは、異なるMLOpsプロセスと統合される。
キャプチャされるMLメタデータには、パイプラインの実行ID、トリガー、プロセスタイプ、ステップ、開始・終了日時、ステータス、環境構成、入力パラメータ値など。
MLメタデータトラッキングにより、再現性と系列追跡のために実験パラメータやパイプライン構成を追跡することができる。
また、ユーザーはMLモデルやアーティファクトを検索、発見、エクスポートできるようになる。
MLメタデータトラッキングは、異なる実験や実行のメタデータとアーティファクトを分析、比較、視覚化するツールを提供し、問題の特定と解決を支援する。
3.7.2.2 Model governance
モデルガバナンスは、モデルの登録、レビュー、検証、承認に関するプロセス。
モデルガバナンスは以下のタスクを実行する
- 保存: モデルのプロパティを追加・更新し、バージョンや変更を追跡
- 評価: 新しいモデルをチャンピオンモデルと比較。評価メトリックスとビジネスKPIを使用して、モデルの品質を確認。
- チェック: リスクを管理するためにモデルをレビュー、リクエスト変更、承認する
- リリース: モデルデプロイプロセスを呼び出し、本番環境へ移行
- レポート: 継続的な評価から収集されたモデルのパフォーマンスメトリックスを集計・可視化
4. Putting it all together
MLでビジネス価値を提供することは、ビジネス環境の変化に適応する統合されたMLシステムを構築すること。
以下の要素が含まれる
本ドキュメントでは以下の説明を行った
- MLシステムの構築および運用のためのコア機能
- 開発から本番環境へのワークフローを効率化する包括的MLOpsプロセス
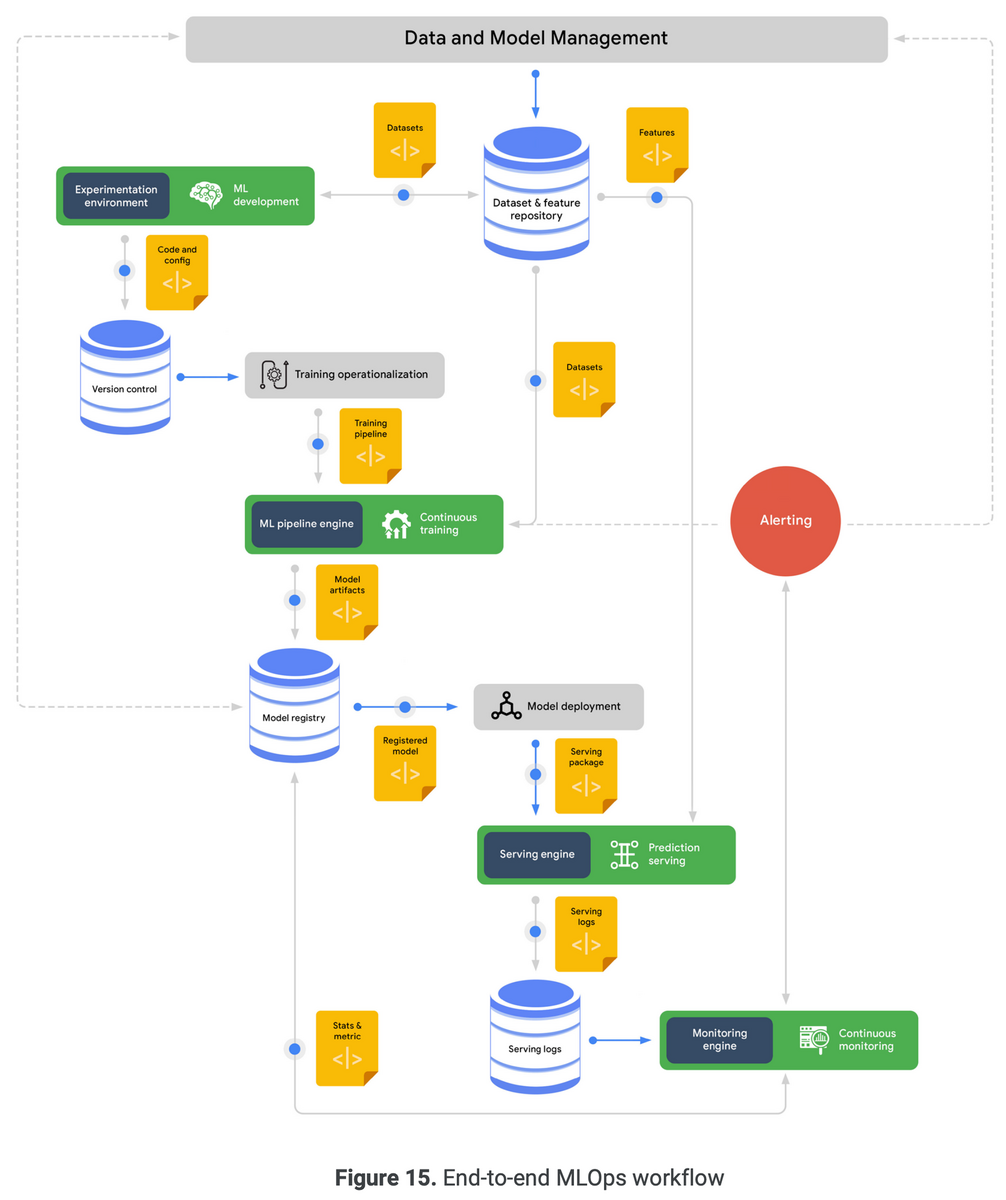
Figure 15