Data Engineering Study #23 Data orchestration 特集の発表「ワークフローオーケストレーション入門」から、ワークフローオーケストレーションの歴史について記事にまとめました。
概要
近年データエンジニアリングの周辺技術が話題に上がるようになり、ワークフローオーケストレーションが注目を集めています。

上図はワークフローオーケストレーションの関連ワードのGoogle Trendです。
データオーケストレーションを中心として、ワークフローオーケストレーション関連語の検索数が上昇傾向にあります。
本記事では最新のワークフローオーケストレーションの動向を知るために、ワークフローオーケストレーションの歴史を深ぼります。
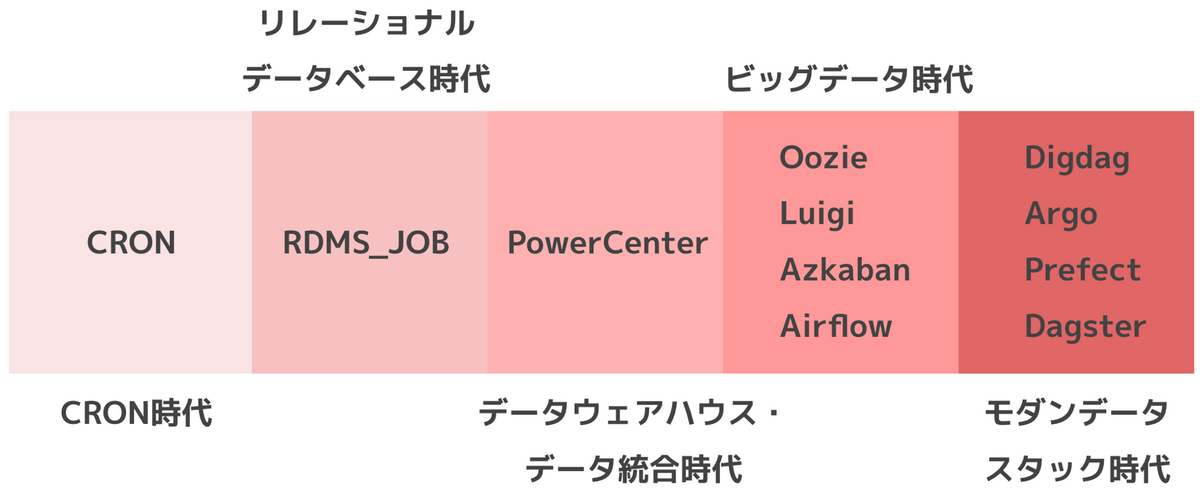
Prefect社のブログ記事 A Brief History of Workflow Orchestration をもとに、ワークフローオーケストレーションの歴史を5つの時代に区分しました。
- CRON時代
- リレーショナルデータベース時代
- データウェアハウス・データ統合時代
- ビッグデータ時代
- モダンデータスタック時代
各時代の主要なツールをまとめると以下のように変遷してきています。
CRON時代
ワークフローオーケストレーションの歴史はCRONから始まりました。
1974年にUNIXにCRONが導入されました。
機能は指定された時刻にコマンドを実行するというものでした。
以下はCRONコマンドを用いて、一連の処理を記述したシェルスクリプトを定期実行する例です。
0 0 0 1 1 * ./workflow.sh
CRONは特定の処理をスケジュール実行したい場合の手段として使い勝手が良く、現在も幅広く使用されている機能です。
リレーショナルデータベース時代
1979年に商用リレーショナルデータベースのOracle v2がリリースされました。
その後、1995年にOracleがジョブキュー(DBMS_JOB)を導入します。
機能はデータベース用コードの定期的な実行をスケジュールするものでした。
以下は新しくDBMS_JOBジョブを作成するPL/SQLコード例です。
PL/SQL(Procedural Language/Structured Query Language)はOracleデータベースで使用されるプログラミング言語です。
DECLARE job_number NUMBER; BEGIN DBMS_JOB.SUBMIT( job => job_number, what => 'BEGIN YOUR_PROCEDURE_NAME; END;', next_date => SYSDATE, interval => 'SYSDATE + 1' ); COMMIT; END;
DBMS_JOBのようにリレーショナルデータベースの機能の一部として、ジョブのスケジュール実行を行えるようになりました。
データウェアハウス・データ統合時代
データウェアハウスが登場し、データ統合が行われる以前、複数のデータソースごとデータを処理していました。
例えば、アプリケーションデータはCRONで処理し、リレーショナルデータベースは付属機能のジョブを実行するといった状況です。

複数のデータソースからデータを収集・変換し、データウェアハウスに格納するETL処理が主流となってきました。
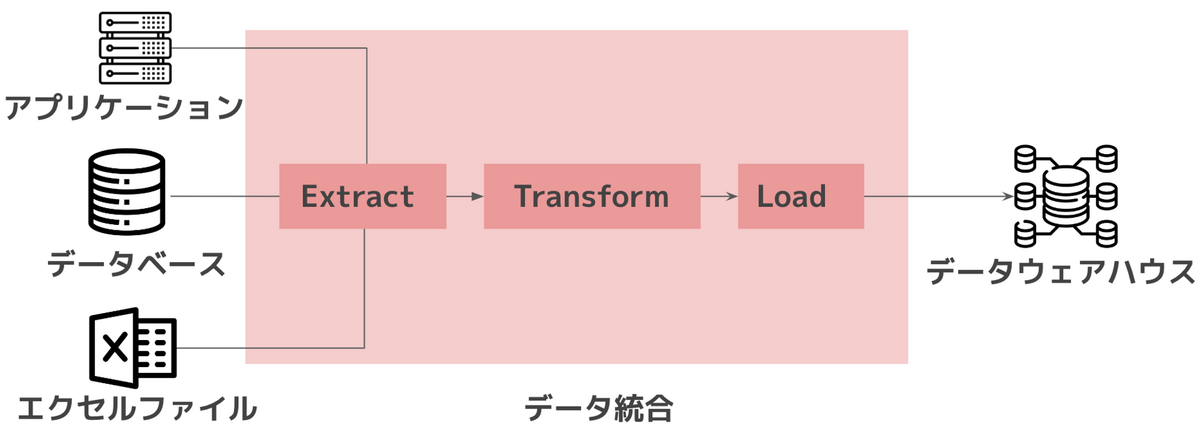
データをソースからターゲットに変換する機能を提供するツールが登場します。
代表的なのは1998年にInformatica社がリリースしたPowerCenterです。
PowerCenterはスケジュールされたジョブの実行・管理を中心としたツールでした。
データ処理のソースとターゲット、2つを繋ぐワークフローの概念が初めて導入されました。
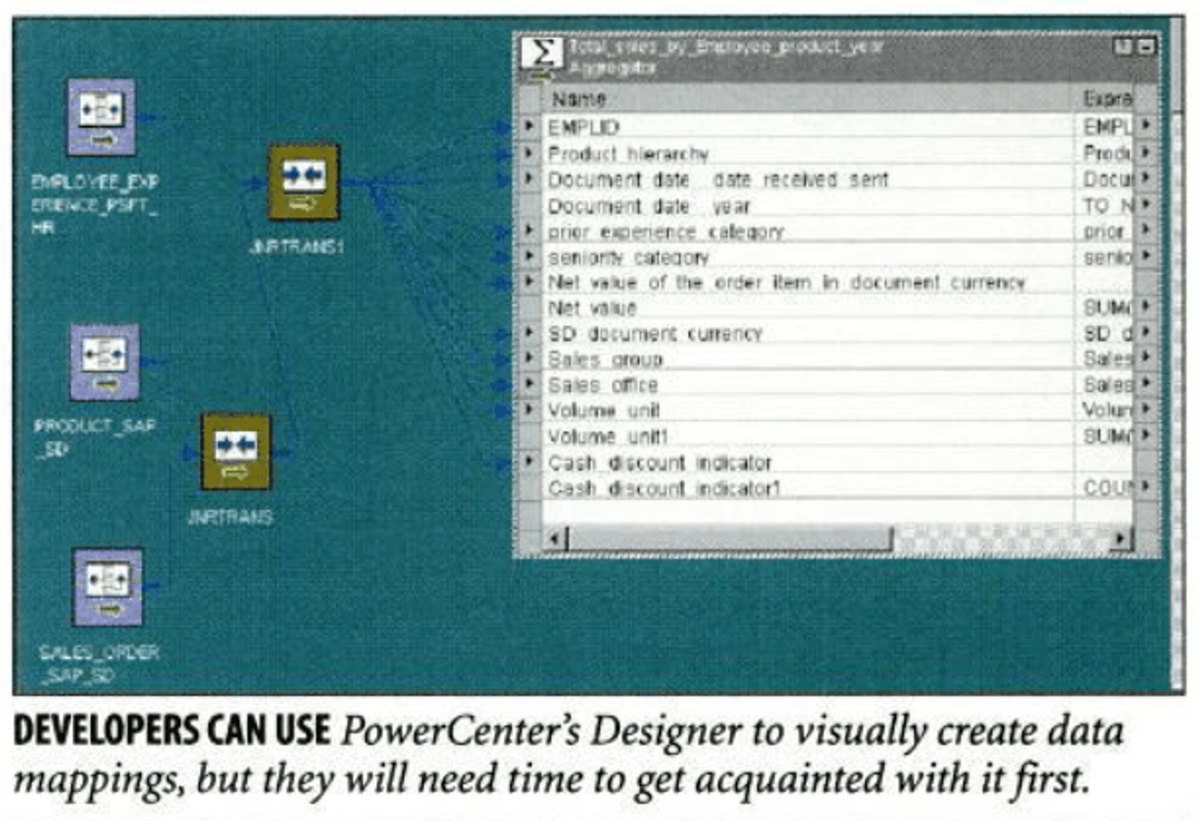
以下はPowerCenterのデータマッピングの設定画面の例です。
ビッグデータ時代
2006年にGoogleがHadoopをOSS化し、2011年にデータレイクが提唱・流行します。
Hadoopにより分散処理が可能となったことで、大量のデータをデータレイクに格納できるようになりました。
格納したデータを活用方法に応じて処理するELT処理が主流となります。
データ基盤構築はオンプレ環境のHadoopエコシステムで作られるケースが増えてきました。
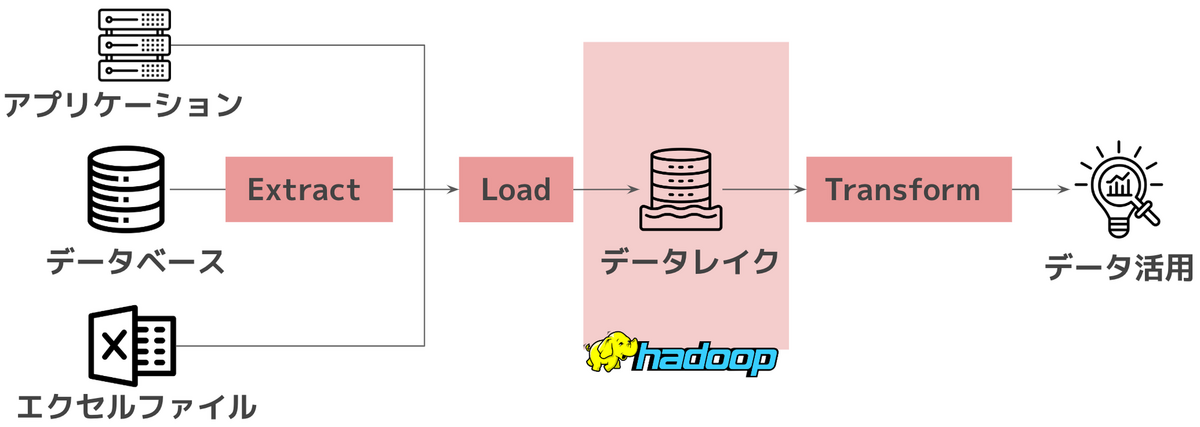
Hadoopエコシステムを活用するためのワークフローオーケストレーションツールが登場します。
これらのツールはワークフローツール第一世代と呼ばれることが多いです。
代表的なツールだとOozie, Luigi, Azkabanがあります。いずれのツールもHadoopジョブを管理する機能がGitHubのREADMEに記述されています。
現在も使用例が多いAirflowはワークフロー管理のプラットフォームの立ち位置ですが、時代背景的にはHadoopジョブの管理の課題感から生まれたツールになっています。

モダンデータスタック時代
2011年 BigQuery(GCP)がGA、2013年 Redshift(AWS)がGA, Sparkを事業化したDatabricks社が設立、2014年 SnowflakeがGA、Kafkaを事業化したConfluent社が設立されます。
新しい技術の登場により、データ基盤に変化が起きました
- オンプレから安価で高速なクラウドにデータ基盤がシフト
- ストリームデータ処理技術が発達
このような新しいデータ基盤の課題を解決するツールに対し、Modern Data Stackという言葉を当てるようになりました。
Data Stackはデータ基盤を構成する製品群を意味します。Modern Data Stackは従来のData Stackの課題を解決しようとする技術トレンドの総称で、特定のアーキテクチャ・技術・ソリューションを指す言葉ではありません。
データ活用領域のトレンド「Modern Data Stack」に関するホワイトペーパーを公開 | NTTデータグループ - NTT DATA GROUP
Emerging Architectures for Modern Data Infrastructure: 2020 | Andreessen Horowitz の記事でデータ基盤技術の変化がまとめられています。技術トレンドの変化に、ワークフローオーケストレーションが含まれています。

Modern Data Stackと呼ばれるような新たなワークフローオーケストレーションツールが登場し始めました。
2016年 DigdagがOSS化、StepFunctions(AWS)がGA、2017年 Prefectがリリース、ArgoがOSS化、2018年 Dagsterがリリース、2019年 CloudComposer(GCP)がGA
これらはワークフローツール第二世代と呼ばれ、次世代のワークフローツールとして近年注目を集めています。
まとめ
ワークフローオーケストレーションの歴史を5つの時代に区分し、各時代の主要なツールを以下のようにまとめました。
データ基盤がオンプレからクラウドへ移り変わり、Modern Data Stackと呼ばれる新しいツールを組み合わせてデータ基盤を構築するのが現代の主流となりました。
この技術トレンドの変化からワークフローオーケストレーションの注目が集まってきていると言えます。