
Pythonのメモリプロファイルを行うためにmemrayを使用したところ、インストールからプロファイル実行まで手軽にでき、レポート方法が豊富で使い勝手が良かったので使用方法を紹介します。
本文中コード:code-for-blogpost/memray at main · nsakki55/code-for-blogpost · GitHub
Memrayとは
2022年4月にBloombergが公開したPythonのメモリプロファイルツールです。
公式ドキュメント:https://bloomberg.github.io/memray/
公式ドキュメントではMemrayの特徴を以下のように記述しています。
- トレーシングプロファイルを行うため、呼び出しスタックを正確に表現できる
- C/C++ライブラリのネイティブ呼び出しも扱えるため、結果には全ての呼び出しスタックが含まれる
- 高速
- メモリ使用に関するさまざまなレポートを生成できる
- Pythonスレッドと連携
- ネイティブスレッド(ネイティブ拡張機能内のC++スレッド)と連携
対応環境
検証環境
$sw_vers ProductName: macOS ProductVersion: 11.3.1 BuildVersion: 20E241 $ python --version Python 3.8.7
インストール
pipでインストールすることができます。
$ pip install memray
実行方法
メモリプロファイル実行
run コマンドでプロファイルしたいファイル、モジュールを指定することでメモリプロファイルを実行できます。
The run subcommand - memray
memray run [options] {対象ファイル} [args]
memray run [options] -m {module} [args]
実行が完了すると memray-<script>.<pid>.bin というファイル名で、実行結果のバイナリファイルが作成されます。
memrayでは run コマンドで作成したバイナリファイルをもとに、メモリ使用に関するレポートを作成します。
試しにiris dasasetをLightGBMで学習するスクリプト train.pyでメモリプロファイルを実行してみます。
from typing import Tuple import lightgbm as lgb import numpy as np from sklearn import datasets from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split def load_dataset() -> Tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]: iris = datasets.load_iris() X, y = iris.data, iris.target X_train, X_test, y_train, y_test = train_test_split(X, y) return X_train, X_test, y_train, y_test def train(X_train: np.ndarray, y_train: np.ndarray) -> lgb.LGBMClassifier: model = lgb.LGBMClassifier() model.fit(X_train, y_train) return model def validate(model: lgb.LGBMClassifier, X_test: np.ndarray, y_test: np.ndarray) -> None: y_prob = model.predict_proba(X_test) y_pred = np.argmax(y_prob, axis=1) accuracy = accuracy_score(y_test, y_pred) print(f"accuracy: {accuracy}") def main() -> None: X_train, X_test, y_train, y_test = load_dataset() model = train(X_train, y_train) validate(model, X_test, y_test) if __name__ == "__main__": main()
memray run を実行すると、train.pyのスクリプトが実行され、バイナリファイルが作成されます。
$ memray run train.py ... [memray] Successfully generated profile results. You can now generate reports from the stored allocation records. Some example commands to generate reports: /Users/satsuki/.pyenv/versions/3.8.7/envs/data-science/bin/python3.8 -m memray flamegraph memray-train.py.99131.bin
実行が完了すると、memray-train.py.99131.binというファイルが作成されます。
結果をリアルタイム出力
run コマンドに —live 引数をつけることで、実行中のスクリプトのメモリ使用状況を見ることができます。
Live Reporting - memray
$ memray run --live {対象ファイル}
train.pyのメモリ使用状況をリアルタイム出力してみます。
$ memray run --live train.py

以下の指標が出力されます
- Total Memory
- 関数とその内部で呼び出されてる関数に割り当てられた累積メモリ量
- Own Memory
- 関数に直接割り当てられたメモリ量
- Allocation Count
- 関数とその内部で呼び出されてる関数によって解放されていない累積割り当て数
--live-remote 引数を加えることで、プロファイラを実行するコンソールとは別のコンソールで結果をリアルタイム出力できます。
$ memray run --remote-live {対象ファイル}
実行すると、別コンソールで結果を出力するためのport番号が表示されます。
$ memray run --remote-live train.py Run 'memray3.8 live 60627' in another shell to see live results
port番号を使用して、別コンソールで結果を表示することができます
$ memray live <port>
train.pyの実行では、以下のコマンドで結果を確認することができます。
$ memray live 60627
summaryを出力
run コマンドで作成した結果のバイナリファイルを使用して、メモリ使用状況のsummaryをCLIで表示できます。
Summary Reporter - memray
$ memray summary {結果バイナリファイル}
プロセスのメモリ使用量がピーク時のメモリ使用状況の概要を見ることができます。
train.pyのプロファイル結果を使用して、summaryを表示してみます。
$ memray summary memray-train.py.99131.bin
以下のように、コンソールにプロファイル結果の概要が出力されます。
—live 引数でリアルタイム出力した結果と同様の指標が表示されます。

Flame Graphで結果を出力
Flame Graph形式でプログラムがどの部分でメモリを使用してるか視覚的に確認することができます。
Flame Graph Reporter - memray
$ memray flamegraph {結果バイナリファイル}
メモリ使用状況の時間変化や、メモリ使用量が多い関数を視覚的に表したFlame Graphを作成します。
train.pyのプロファイル結果を使用して、Flame Graphを作成してみます。
$ memray flamegraph memray-train.py.99131.bin Wrote memray-flamegraph-train.py.99131.html
memray-flamegraph-train.py.99131.html ファイル名のHTMLが作成されます。
出力されたHTMLを開くと、以下のように実行結果を視覚的に確認できます。

メモリ使用状況のグラフをクリックすると、詳細を見ることができます。
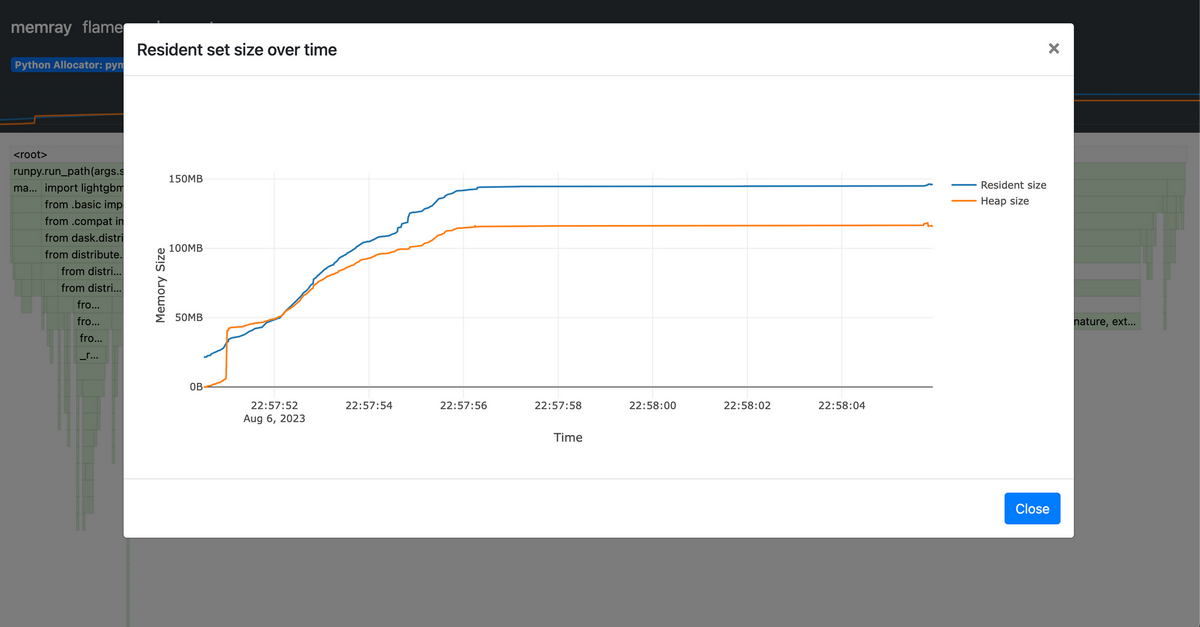
2種類のメモリサイズが表示されます。
- Resident size:物理メモリ上に確保されたメモリサイズ
- Heap size:アプリケーションが確保したメモリサイズ
特定の関数に絞ってメモリ使用状況を確認できます。例えばmain関数をクリックすると、main関数内でのメモリ使用状況を詳しく見ることができます。 train関数で2.8MBのメモリを確保してることが分かります。

表形式で結果を出力
メモリ使用状況を表形式で出力できます。
Table Reporter - memray
$ memray table {結果バイナリファイル}
train.pyのプロファイル結果を使用して、表形式で確認してみます。
$ memray table memray-train.py.99131.bin Wrote memray-table-train.py.99131.html
memray-table-train.py.99131.html ファイル名のHTMLが作成されます。
以下のように、各処理で確保されたメモリの一覧を表形式で見ることができます。

ツリー構造で結果を出力
メモリ使用状況をツリー構造で出力できます。
Tree Reporter - memray
$ memray tree <結果バイナリファイル>
各ノードは関数を表して、関数がどの関数から呼び出されているかが分かります。
train.pyのプロファイル結果を使用して、ツリー構造を出力してみます。
$ memray tree memray-train.py.99131.bin
以下のように、関数ごとのメモリ使用状況をツリー構造で表した結果がコンソールに出力されます。

メモリ使用の統計情報を出力
メモリプロファイルの統計情報を出力できます。
Stats Reporter - memray
$ memray stats <結果バイナリファイル>
train.pyのプロファイル結果を使用して、statsコマンドを実行します。
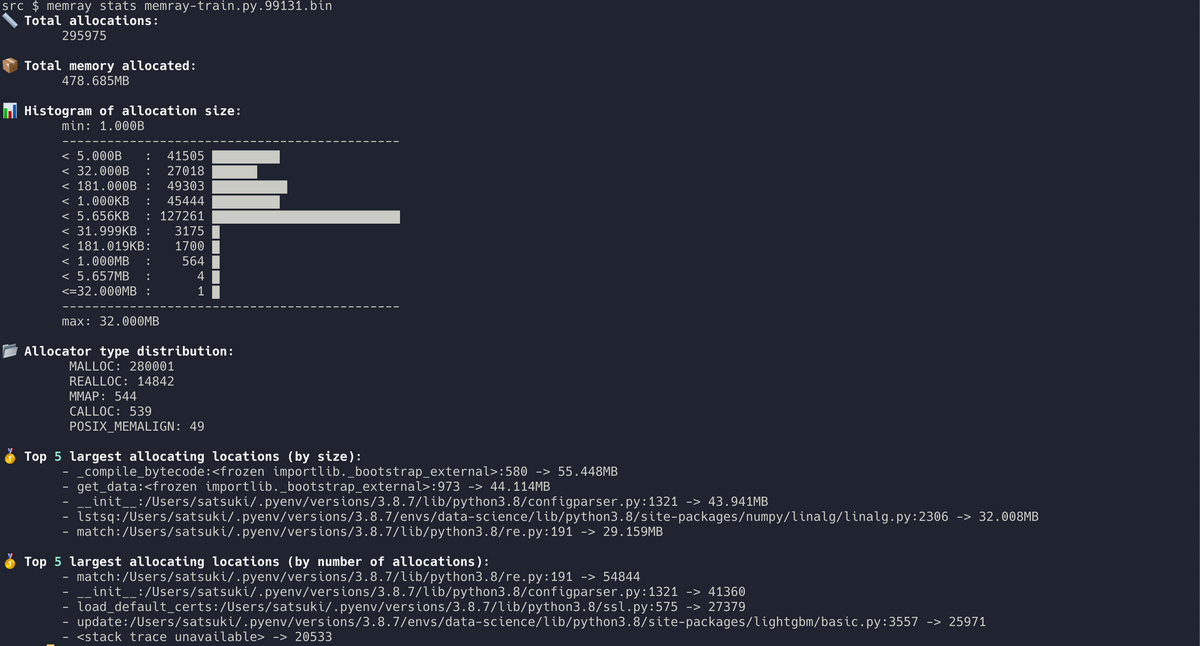
$ memray stats memray-train.py.99131.bin
6つの値が出力されます
- メモリ割り当て回数
- 割り当てられたメモリ合計
- 割り当てメモリサイズのヒストグラム
- 割り当てタイプの分布 (MALLOC、CALLOC、MMAP…etc)
- 割り当てメモリサイズ上位の処理
- メモリ割り当て回数上位の処理
実行すると、メモリ使用の統計情報がコンソールに出力されます。
外部ツールが扱える形式で出力
外部ツールが扱えるデータ形式に結果を変換できます。
Transform Reporter - memray
$ memray transform <出力形式> <結果バイナリファイル>
サポートされているファイル形式は2つです。
- gprof2dot
- csv
gprof2dot
gprof2dotツールと互換性のあるJSONを出力します。
graphvizを使用することで、メモリ使用量をグラフ表示できます。
train.pyのプロファイル結果を使用して、gprof2dotのグラフを書いてみます。
$ memray transform gprof2dot memray-train.py.99131.bin Wrote memray-gprof2dot-train.py.99131.json To generate a graph from the transform file, run for example: gprof2dot -f json memray-gprof2dot-train.py.99131.json | dot -Tpng -o output.png
実行するとJSONが作成され、graphvizでグラフを書くためのコマンドが出力されます。
graphvizがインストールされていない場合、以下のコマンドでインストールしておきます。
$ brew install graphviz
出力されたコマンドを実行すると、グラフが出力されました。
$ gprof2dot -f json memray-gprof2dot-train.py.99131.json | dot -Tpng -o output.png
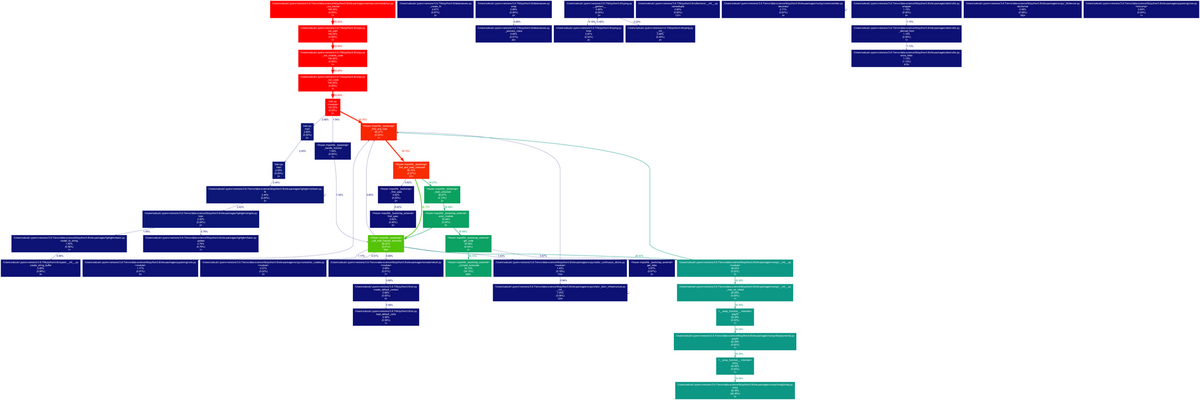
各ノードには以下の値が表示されます
- total %: 関数とその子ノードの使用メモリの割合
- self %:関数単体の使用メモリの割合
- num_allocs:関数単体でのメモリ割り当ての回数
csv
データ分析がしやすいcsv形式で出力します。
train.pyのプロファイル結果を使用して、csvを作成してみます。
memray transform csv memray-train.py.99131.bin
memray-csv-train.py.99131.csv というファイル名で以下のようなcsvが出力されました。

jupyter環境で使用する
jupyterノートブック上で、セルごとのメモリ使用状況をmemrayで可視化できます。
Jupyter Integration - memray
IPythonの拡張プラグインを読み込むことで、利用できるようになります。
以下のコマンドをjupyterノートブックで実行することで、memrayの拡張プラグインを使用できるようになります。
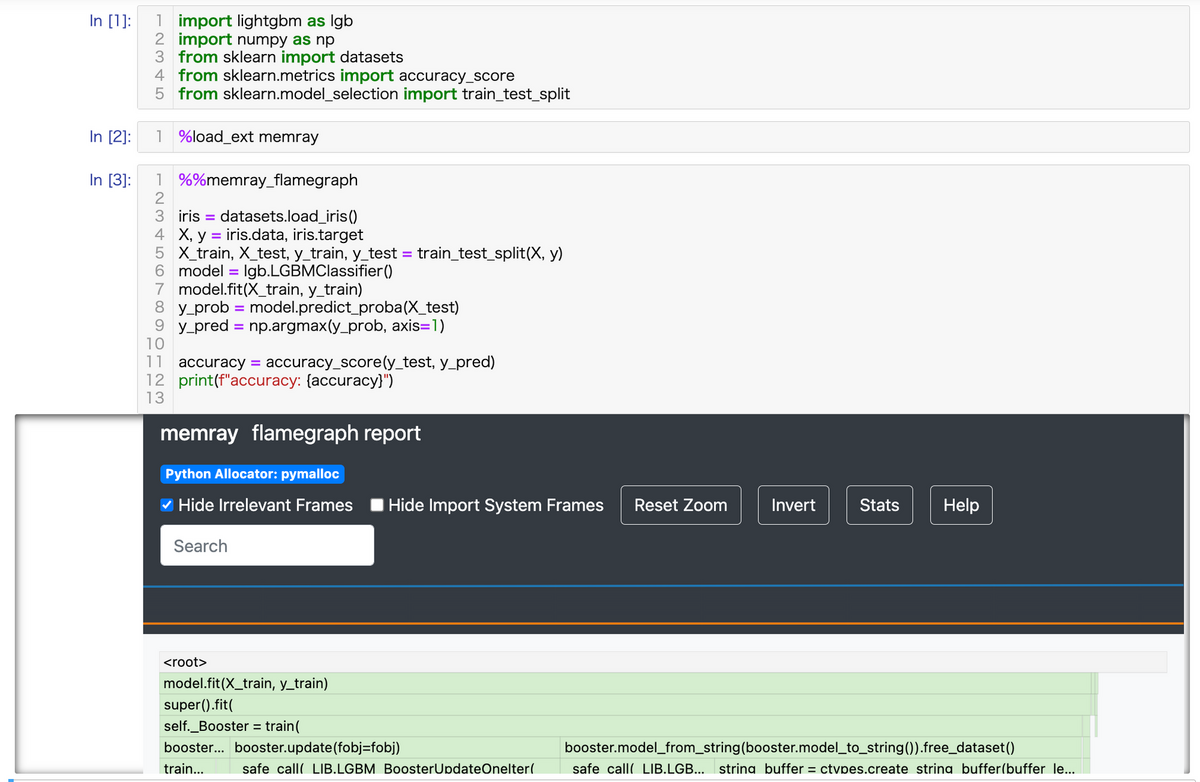
%load_ext memray
上記のコマンドを実行後、 %%memray_flamegraph というマジックコマンドが実行可能になります。このコマンドを、メモリプロファイルを行いたいセルの上部に加えて実行することで、プロファイル結果を表示できます。
Python APIを使用する
memrayではwithステートメントを利用して、pythonコード中にメモリプロファイルを組み込むことができます。
Memray API - memray
memrayのPythonAPIが提供してる、Trackerクラスをコンテクストマネージャーとして使用することで、部分的にメモリプロファイルを実行できます。
with memray.Tracker("結果バイナリファイル名"):
winステートメントを利用して、先程の学習スクリプトの中でモデル学習部分のみメモリプロファイルを実行してみます。
import lightgbm as lgb import memray import numpy as np from sklearn import datasets from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split def main(): iris = datasets.load_iris() X, y = iris.data, iris.target X_train, X_test, y_train, y_test = train_test_split(X, y) with memray.Tracker("memray-train.bin"): model = lgb.LGBMClassifier() model.fit(X_train, y_train) y_prob = model.predict_proba(X_test) y_pred = np.argmax(y_prob, axis=1) accuracy = accuracy_score(y_test, y_pred) print(f"accuracy: {accuracy}") if __name__ == "__main__": main()
memray-train.bin というファイル名で結果が出力されます。
このバイナリファイルを使用して、flamegraph形式で結果を出力してみると、モデル学習部分のメモリ使用状況が可視化されました。
$ memray flamegraph memray-train.bin

まとめ
メモリプロファイラツールmemrayを紹介しました。
Pythonメモリプロファイルツールで有名なのはmemory-profilerですが、結果のレポート方法が豊富で、視覚的に分かりやすい memrayを利用してみてはいかがでしょうか。
本文中コード:code-for-blogpost/memray at main · nsakki55/code-for-blogpost · GitHub