SageMaker で学習ジョブを実行する ~組み込みアルゴリズム~ - nsakki55 のアウトプットブログの続きの内容です
記事中のコード
SagaMaker を用いたモデルの学習
SageMaker では学習に必要なスクリプトやライブラリをコンテナベースで管理し、学習に必要なインフラ管理を自動で行なってくれます。
思想としては、データサイエンティストが面倒なインフラ管理や推論サービスの作業を行わず、MLモデルの開発に集中できることが SageMaker を使用するメリットとなっています。
SageMaker Training Jobが行なっていることは、大きく分けると以下の流れになります
- S3から入力データを読み込み
- 学習用コンテナを実行
- モデルアーティファクトをS3に書き戻す
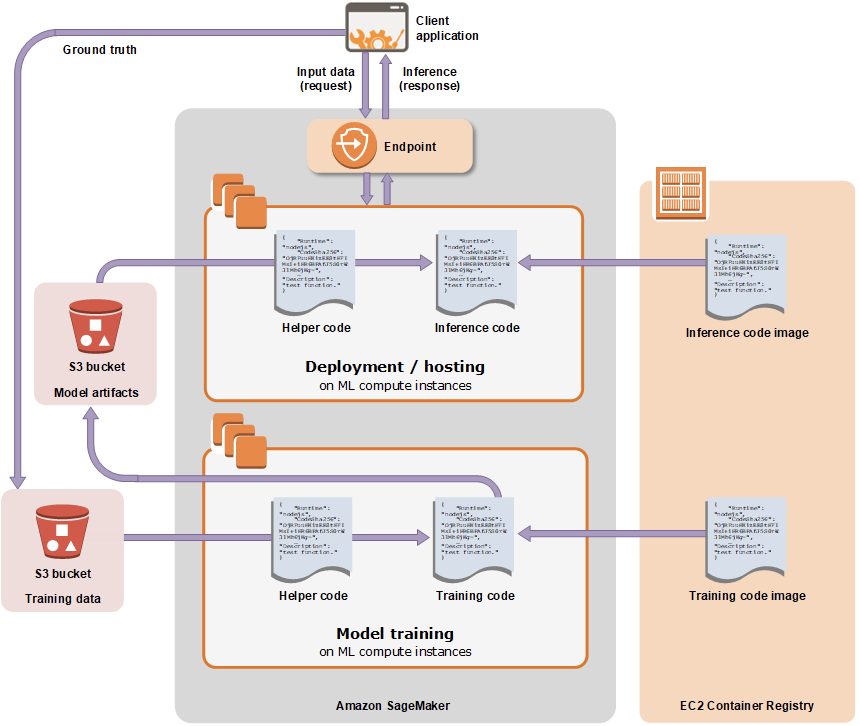
引用: Amazon SageMaker でモデルをトレーニングする - Amazon SageMaker
データ入出力を利用するためのデータパスの対応や、コンテナ環境の準備など、SageMaker で学習を実行するためのルールがあります。
SageMakerで学習を実行する場合、3つパターンが存在します
- 組み込みアルゴリズム : AWSが提供するコンテナ・学習スクリプトを実行
- 独自スクリプト: AWSが提供するコンテナ上で、独自スクリプトを実行
- 独自コンテナ: 独自スクリプトを含めた独自コンテナを実行
コード量を少なくし手軽にモデルの学習を実行できるのは組み込みアルゴリズムを利用する場合ですが、実装の柔軟性は低くなります。一方、独自スクリプトや独自コンテナを利用する場合、コード量は増えますが実装の柔軟性は高くなり、独自のアルゴリズムでの学習を実行することができるようになります。

初めてSageMakerでモデルの学習を実行する際、実行パターンの多さ・守るルールの多さに面食らってしまう人が多いと思います。ドキュメントやサンプルコードは豊富に提供されていますが、どのパターンの学習方法で、最低限必要な要素は一体何なのかを把握するのが大変です。
SageMaker ではモデル学習のために以下のようなサービスを提供してくれていますが、本記事では扱いません。
- HyperparameterTuning
- SagaMaker Model Monitoring
- Clarify
- Debugger
- Endpoint
...
本記事では独自スクリプトを用いてSageMaker 学習ジョブで実行します SageMaker 学習ジョブを実行するには AWS SDK, SageMaker SDKを用いる2つの方法がありますが、今回は jupyter notebook から学習をジョブを実行するため、SageMaker SDKを使用します。
データセット・モデル
今回は広告をクリックする確率(CTR)を予測を予測する二値分類モデルの学習を行います。
データセットは kaggle のavazu-ctr-predictionのデータセットを使用します。
Click-Through Rate Prediction | Kaggle
特徴量前処理はFeatureHashing を行い、線形回帰モデルを使用します。
独自スクリプト
独自スクリプト(script mode)で学習ジョブを実行する場合、AWSが提供するScikit-Learn や PyTorchなどのライブラリ実行環境が整えられたコンテナを利用して、独自スクリプトを実行します。 Bring Your Own Model with SageMaker Script Mode — Amazon SageMaker Examples 1.0.0 documentation
AWS提供コンテナ環境一覧
公式サンプルコードに、各ライブラリ環境での独自スクリプトの利用ユースケースがまとまっています
AWSが提供するコンテナ環境の実装は公開されています
- TensorFlow/Keras
- PyTorch
- MXNet
- Chainer
- Scikit-Learn
- XGBoost
- Spark ML
- Reinforcement Learning
独自スクリプトの実行パターン
AWSが提供するコンテナ環境で独自スクリプトを実行する場合、3つのパターンがあります
下二つの方法を用いれば、AWS提供のライブラリに環境を簡単に拡張することができます。
より独自の実行環境を用意したい場合はカスタムコンテナの利用を検討することになりますが、本記事では扱いません。

SageMakerで独自スクリプトを実行する流れ
Script Mode で学習ジョブをSageMaker上で実行する流れは以下のようになっています

- 学習データの準備 (S3にアップロード)
- 学習スクリプトの準備
- 学習設定を渡した学習ジョブをSageMakerで実行
AWS提供のコンテナにインストールされているSageMaker Training Toolkit ライブラリの環境変数を用いて、SageMaker のコンテナ内に学習データ・学習スクリプト・学習設定を受け渡すことができます。
SageMaker で独自スクリプトを実行する場合、これらのデータ受け渡しのルールに従って学習スクリプトを記述する必要があります。
個人的な所感ですが、DSが手軽にSageMakerで学習を実行するまでの学習コストが高いなと思います。SageMaker がホスティングするコンテナにデータ・ハイパーパラメータを受け渡すためのルールが独特で、慣れるまで時間がかかると思います。
SageMaker Trainig Toolkit の環境変数
AWS提供のコンテナ環境には、SageMaker Training Toolkit という、ユーザーが用意したデータ・スクリプト・学習設定をコンテナ内に受け渡し、学習ジョブを実行するためのライブラリがインストールされています。
SageMaker Training Tookit によって、SageMaker がスクリプトに渡す環境変数の一部を紹介します
独自スクリプトを実行する際は、下記の環境変数をスクリプト中に記述して、外部からのデータの受け渡しを行います。 sagemaker-training-toolkit/ENVIRONMENT_VARIABLES.md at master · aws/sagemaker-training-toolkit · GitHub
- SM_MODEL_DIR
- 学習済みモデルを格納するディレクトリ
/opt/ml/model
- 学習済みモデルを格納するディレクトリ
- SM_INPUT_DIR
- 入力データを格納するディレクトリ
/opt/ml/input/
- 入力データを格納するディレクトリ
- SM_INPUT_CONFIG_DIR
- 入力設定を格納するディレクトリ
/opt/ml/input/config
- 入力設定を格納するディレクトリ
- SM_CHANNELS
- train, validation, test など入力データのS3ロケーション
- SM_CHANNEL_{channel_name}
- 各channel(入力データ)を格納するディレクトリ. channel=training の場合
SM_CHANNEL_TRAINING=/opt/ml/input/data/training
- 各channel(入力データ)を格納するディレクトリ. channel=training の場合
- SM_OUTPUT_DATA_DIR
- 評価結果と他の訓練に関係しない出力データを格納するディレクトリ
opt/ml/output
- 評価結果と他の訓練に関係しない出力データを格納するディレクトリ
- SM_HPS
- アルゴリズムで使われるハイパーパラメータ
- SM_CURRENT_HOST
- 現在のインスタンスのユニークなホスト名
- SM_HOSTS
- SM_NUM_GPUS
- SM_NUM_CPUS
- 現在のインスタンスのCPU数
- SM_LOG_LEVEL
- 学習スクリプトで使われるログレベル
- SM_USER_ARGS
- ユーザーが指定する追加引数
SM_USER_ARGS='["--batch-size","256","--learning_rate","0.0001"]'
- ユーザーが指定する追加引数
AWSが提供するコンテナ環境で行われる処理
AWS提供のコンテナ環境内部で行われている処理を確認します。今回はScikit-Learn環境を使用するため、https://github.com/aws/sagemaker-scikit-learn-containerの実装を取り上げます。
学習ジョブを実行すると、sagemaker training toolkit の entry_point.py中のrunメソッドを呼び出しています。
from __future__ import absolute_import import logging from sagemaker_training import entry_point, environment, runner logger = logging.getLogger(__name__) def train(training_environment): """Runs Scikit-learn training on a user supplied module in local SageMaker environment. The user supplied module and its dependencies are downloaded from S3. Training is invoked by calling a "train" function in the user supplied module. Args: training_environment: training environment object containing environment variables, training arguments and hyperparameters """ logger.info('Invoking user training script.') entry_point.run(uri=training_environment.module_dir, user_entry_point=training_environment.user_entry_point, args=training_environment.to_cmd_args(), env_vars=training_environment.to_env_vars(), runner_type=runner.ProcessRunnerType) def main(): train(environment.Environment())
sagemaker training toolkit の entry_point.py のrunメソッドのdocstring を見てみます。
「entry point として設定されたS3, フォルダから圧縮したtarファイルをダウンロード・準備を行い、環境変数(env_vars)と、コマンドライン引数(args)を渡してユーザーが設定した entry point を実行する」と実行内容が記述されています
entry point ごとに以下のコマンドが実行されます
python パッケージ : env_vars python -m module_name + args
python スクリプト : env_vars python module_name + args
その他 : env_vars /bin/sh -c ./module_name + args
def run( uri, user_entry_point, args, env_vars=None, wait=True, capture_error=False, runner_type=runner.ProcessRunnerType, extra_opts=None, ): """Download, prepare and execute a compressed tar file from S3 or provided directory as a user entry point. Run the user entry point, passing env_vars as environment variables and args as command arguments. If the entry point is: - A Python package: executes the packages as >>> env_vars python -m module_name + args - A Python script: executes the script as >>> env_vars python module_name + args - Any other: executes the command as >>> env_vars /bin/sh -c ./module_name + args
独自スクリプトをAWS提供コンテナ環境で実行する場合、環境変数とコマンドライン引数を渡してスクリプトが内部で実行されていることが確認できます。
SagaMaker 学習ジョブの内部処理が気になる方は、各ライブラリ環境の実装と、sagemaker trainig toolkit の実装を一度見てみることをお勧めします。
AWS提供のコンテナ環境で実行する方法
SageMaker で独自スクリプトを実行する手順は3つです
- 学習データの準備 (S3にアップロード)
- 学習スクリプトの準備
- 学習設定を渡した学習ジョブをSageMakerで実行
学習データの準備 (S3にアップロード)
学習ジョブ実行時に渡す学習用データをS3にアップロードします
SageMaker SDK に渡す設定を読み込み、データをtrain, validation, test に分割してS3にアップロードします
gistdf57800403f45b3a2f5a505b65679ec4
S3 にデータがアップロードされていることを確認できます

学習スクリプトの準備
データの読み込み→学習→モデル保存の一連の流れを実装した学習スクリプトを用意します。
以下のファイルをsklearn_script_mode.py として保存します.
ポイントは以下の点になります
- コマンドライン引数で学習ハイパーパラメータを受け取る
- 入力データ・学習モデルの読み込み、書き込みパスを環境変数で取得する
独自スクリプトを記述する際は、上記2点さえ注意すれば基本的にMLモデルの学習に限らずどのような処理を記述しても動作します。
gist5625192bbe12d745020cb329ae6b5291
学習設定を渡した学習ジョブをSageMakerで実行
今回はscikit-learn を使用するため、SKLearn Estimatorクラスを使用します。
独自スクリプトを実行する場合、entrypoint に実行スクリプト名、source_dir に実行スクリプトのディレクトリ名を設定します。
entrypoint に指定するスクリプトはS3上のファイルも指定することが可能です。
instance_type に local を指定すると、ローカル環境上で学習ジョブを実行することができます。
以下のようなディレクトリ構成で実行します。
src
├── script_mode_trainer.ipynb
│
└── custom_script
└── sklearn_script_mode.py
fit メソッドを呼び出すことで学習ジョブを SageMaker で実行できます。この時学習データのS3パスを指定します。
gistc68517790baaa738443c0db77aa40177
SageMaker のコンソール画面から学習ジョブが実行できていることを確認できます
学習ジョブのCloud Watchログを見ると、スクリプト実行開始時にsagemaker training toolkit の環境変数一覧が表示されています。


S3に学習済みモデルや、学習ジョブに関わる設定ファイルがアップロードされています

AWS提供のコンテナ環境に3rd party ライブラリを追加して実行する方法
3rd party ライブラリとしてOptuna をインストールして、学習スクリプト中でハイパーパラメータチューニングを行う学習ジョブを実行してみます
学習データの準備 (S3にアップロード)
「AWS提供のコンテナ環境で実行する方法」で既にS3にデータをアップロード済みなので省略
学習スクリプトの準備
3rd partyライブラリをAWS提供のコンテナ環境にインストールして使用する場合、学習スクリプトと同じフォルダ以下にrequirements.txt を配置すると、学習ジョブ実行時に自動でインストールが行われます。
sagemaker trainig toolkit の requirements.txt を検出してインストールする部分の実装を確認してみます。
entry_point.run 内部でinstall メソッドが呼び出され、依存関係のインストールが行われています
def install(name, path=environment.code_dir, capture_error=False): """Install the user provided entry point to be executed as follows: - add the path to sys path - if the user entry point is a command, gives exec permissions to the script Args: name (str): Name of the script or module. path (str): Path to directory where the entry point will be installed. capture_error (bool): Default false. If True, the running process captures the stderr, and appends it to the returned Exception message in case of errors. """ if path not in sys.path: sys.path.insert(0, path) entry_point_type = _entry_point_type.get(path, name) if entry_point_type is _entry_point_type.PYTHON_PACKAGE: modules.install(path, capture_error) elif entry_point_type is _entry_point_type.PYTHON_PROGRAM and modules.has_requirements(path): modules.install_requirements(path, capture_error) if entry_point_type is _entry_point_type.COMMAND: os.chmod(os.path.join(path, name), 511)
has_requirements メソッドでrequirements.txt の存在有無をチェックしています
def has_requirements(path): # type: (str) -> None """Check whether a directory contains a requirements.txt file. Args: path (str): Path to the directory to check for the requirements.txt file. Returns: (bool): Whether the directory contains a requirements.txt file. """ return os.path.exists(os.path.join(path, "requirements.txt"))
requirements.txt が存在する場合、 install_requreiments が呼び出されpip install -r requirements.txt が実行されることを確認できました。
以上の処理が学習ジョブの内部で実行されることで、3rd party ライブラリがインストールされます。
third_party_library フォルダ以下に requirements.txt を用意します
gist89220b7838c4ec95873fec086bdb1bdd
optuna を読み込み、ハイパーパラメータチューニングを行う処理を学習スクリプトに実装します。
gistf5a0f126bef449db4d09bfe0c5b2af8d
学習設定を渡した学習ジョブをSageMakerで実行
reqirements.txt で3rd party ライブラリをインストールする場合、Estimator クラスに特別渡す必要がある引数はありません。学習ジョブの実行開始時に、自動的にrequirements.txt を検出してライブラリをインストールしてくれます。
以下のフォルダ構成で学習ジョブを実行します。
requirements.txt を、実行する学習スクリプトと同じフォルダ内に配置します。
src
├── third_party_library_scirpt_mode_trainer.ipynb
│
└── third_party_library
├── third_party_library_scirpt_mode.py
└── requirements.txt
gist4f9f9d1d296b2e7fad722ed3f07adf07
学習ジョブが実行できていることを確認できます

学習ジョブのCloud Watch ログを確認すると、学習スクリプトの実行開始時に /miniconda3/bin/python -m pip install -r requirements.txt が実行されていることを確認できます。

注意点として、requirements.txt でインストールする場合、実行順序が担保されません。そのため、依存関係があるライブラリをインストールする場合は、requirements.txt に依存関係のないライブラリだけ記述して、学習スクリプト内でsubprocess などを用いて明示的に後からインストールする必要があります。ex) subprocess.run(['pip', 'install', 'optuna'])
ライブラリの依存関係を維持してインストールする手順を classmethod さんのブログで紹介してくれています。
【加藤さん向け】オンプレで動かす機械学習パイプラインをSagemaker用に変更するときのポイント【社内共有】 | DevelopersIO
AWS提供のコンテナ環境に自前ライブラリを追加して実行する方法
学習データの準備 (S3にアップロード)
「AWS提供のコンテナ環境で実行する方法」で既にS3にデータをアップロード済みなので省略
学習スクリプトの準備
学習データの前処理を別ライブラリに切り出して、実行する学習スクリプト中で読み込んでみます。
以下のような前処理の実装を記述した preprocess.py と _init.py をmy_custom_library フォルダ以下に追加します。
gist5997f9ba7bf4e43633eef7fb5d8e4ce9
実行する学習スクリプト側で、preprocess.py中の処理を呼び出します
gista3e01d92e2e5747e163f620a7b771664
学習設定を渡した学習ジョブをSageMakerで実行
自前ライブラリを使用する場合、Estimator クラスのdependencies に自前ライブラリのフォルダ名のリストを指定する必要があります。
公式ドキュメントの説明を見ると、dependencies に設定したフォルダは、entrypoint に設定した学習スクリプトと同じパスでSageMaker のコンテナ中に配置されると説明されています。

Estimators — sagemaker 2.99.0 documentation
sagemaker sdk のEsitmatorで実際に処理される内容を見ると、entrypoint のファイルとdependencies のファイルを格納した圧縮ファイルがS3にアップロードされることがわかります。
def tar_and_upload_dir( session, bucket, s3_key_prefix, script, directory=None, dependencies=None, kms_key=None, s3_resource=None, settings: Optional[SessionSettings] = None, ): """Package source files and upload a compress tar file to S3. The S3 location will be ``s3://<bucket>/s3_key_prefix/sourcedir.tar.gz``. If directory is an S3 URI, an UploadedCode object will be returned, but nothing will be uploaded to S3 (this allow reuse of code already in S3). If directory is None, the script will be added to the archive at ``./<basename of script>``. If directory is not None, the (recursive) contents of the directory will be added to the archive. directory is treated as the base path of the archive, and the script name is assumed to be a filename or relative path inside the directory.
学習ジョブ実行時にこの圧縮ファイルを展開して使用するため、同じパスにdependencies に設定したファイルと、entrypointに設定したファイルが配置されるという理屈です。
今回はmy_custom_library 以下のファイルを読み込むため、[’my_custom_library’]を渡します。
以下のフォルダ構成で独自スクリプト・ライブラリ・実行ノートブックを配置しています
src
├── my_library_script_mode_trainer.ipynb
│
├── my_custom_library
│ ├── __init__.py
│ └── preprocess.py
│
└── custom_script
└── my_library_script_mode.py
gist4827e1568d0db3b91836c6b9fe2a153e
SageMaker のコンソール画面から学習ジョブが実行できていることを確認できます

S3に実行コードの圧縮ファイルがアップロードされています

圧縮ファイルを回答すると、entrypoint と denpendencies のファイルがあることを確認できます。

まとめ
SageMaker 学習ジョブで独自スクリプトを実行する3パターンの方法を取り上げました。AWSが提供するコンテナ内部で行われている処理は sagemaker training toolkit の実装を見ることで確認できます。Script Mode では requirements.txt , 独自ライブラリを追加することでAWS提供のコンテナ環境を拡張することができますが、余計な依存関係を排除して独自のコンテナ環境で学習ジョブを実行する場合はカスタムコンテナを利用します。
参考
- 【加藤さん向け】オンプレで動かす機械学習パイプラインをSagemaker用に変更するときのポイント【社内共有】 | DevelopersIO
- Estimators — sagemaker 2.99.0 documentation
- Amazon SageMaker でモデルをトレーニングする - Amazon SageMaker
- Bring Your Own Model with SageMaker Script Mode — Amazon SageMaker Examples 1.0.0 documentation
- GitHub - data-science-on-aws/data-science-on-aws: AI and Machine Learning with Kubeflow, Amazon EKS, and SageMaker