Amazon Sagemaker Processing を実際にサンプルデータを用いて動かす方法を解説します。 記事中のコード↓ github.com
Amazon Sagemaker Processingとは
Sagemaker Processing はAWSの機械学習マネージドサービスSageMakerの中で、データの処理・モデルの評価などの役割を担うサービスになっています。 https://aws.amazon.com/jp/blogs/news/amazon-sagemaker-processin-fully-managed-data-processing-and-model-evaluation
processingというサービス名の通り、データの処理・モデル評価がユースケースとして取り上げられていますが、Sagamaker Processing は「S3からデータを受け取り、処理を行ったデータをS3へ出力する」という処理を行ってくれるので、データを受け取って出力するという処理なら何でも実行できます。
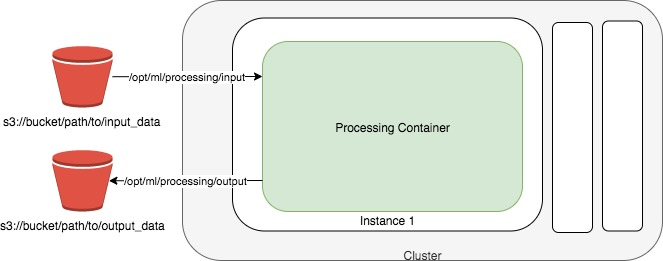
概念図は以下のようなっていて
- 入力データのパス
- 出力データのパス
- 処理内容(スクリプト・docker imageなど)
の3つの要素を指定する必要があります。
Sagemaker Processingでは、処理の実行を行うためのクラスにSKLearnProcessor, PySparkProcessor, Processor, ScriptProcessor の4つのクラスを用意してくれています。
これらのクラスは、行いたい処理内容に応じて使い分ける必要があり
- scikit-learn を使用する : SKLearnProcessor
- Pyspark を使用する: PySparkProcessor
- カスタムコンテナを使用する: ScriptProcessor, (Processor)
のように使用するProcessorクラスを選びます。
ScriptProcessor はProcessorを継承し、SKLearnProcessor, PySparkProcessorはScriptProcessorを継承する関係となっています。つまり、起動コンテナの指定をSKLearnProcessor, PySparkProcessorはインスタンス作成時に内部で行なっているだけで、全てのクラスで起動コンテナの指定→Processorの処理が実行されます。
今回はユースケースが多いと思われる、skicit-learnを使用する KLearnProcessorと、自前実装したコンテナを使用するScriptProcessor で処理を実行する方法を解説します。
実現したい処理
今回は広告をクリックする確率(Click Through Rate)を予測する機械学習モデルの特徴量生成を実装します。
データセットは avazu-ctr-prediction のデータセットを利用します。
https://www.kaggle.com/c/avazu-ctr-prediction
このデータセットに対して、学習・検証データの分割を行い、特徴量処理でFeature Hasingを行う処理をSagemaker Processingで実行してみます。
Feature Hasing について
ユーザー情報やメディア情報を表す特徴は、しばしば要素数の多いカテゴリ特徴量が多い場合が多いです。カテゴリ特徴量はone hot encoding や label encoding などを利用して、MLモデルが利用できるように数値変換しますが、要素数が多いとメモリ効率が悪く扱いが難しくなります。
このような要素数の多いカテゴリ特徴に対してハッシュ化を行い、高次元特徴を事前に定めた次元数に削減した特徴ベクトルに変換する Feature Hasing という手法が存在します。
Feature Hasing の詳しい説明は以下の記事が詳しく書かれています。
全体像
今回実装する処理は以下のような流れになります。

- scikit-learn: SKLearnProcessor
- カスタムコンテナ: ScriptProcessor
の2つの方法で導入します。
SKLearnProcessorを使用する手順
SKLearnProcessorを実行する手順は大まかに以下のようになります
データ準備
https://www.kaggle.com/c/avazu-ctr-prediction からダウンロードした train データを s3://{bukcet}/input/train へ保存します。
S3のパス指定はどこでも大丈夫ですが、input 以下に入力データを置いた方が分かりやすいです。
実際にデータを確認してみます
gist57d1513f418573bd2f89a64c800107e6
データ処理スクリプトを用意
行いたい処理を実装したpython スクリプトを用意します。
実装する項目としては以下の3つです
- 入力データの読み込み
- 任意の処理
- 加工データの保存
Sagemaker Processingのお約束として、実行コンテナ中のデータは、実行時に指定されたパスに保存されるという決まりがあります。
以下のスクリプト中では読み込む学習データのパスを input_train_data_path = os.path.join("/opt/ml/processing/input", "train") とし、加工データの保存パスを os.path.join("/opt/ml/processing/output/train", "train_data") としています。
これはprocessing 処理の実行時に、S3のデータをコンテナ内のどのパスに対応させるかを指定しているため、スクリプト側でデータ操作を行う際は指定したパスに従う必要があるためです。
コンテナのマウント先をS3に指定するような感覚でできることがSagemaker の思想となっています。
コンテナパスは/opt/ml/processing/ で始まる必要があるので注意してください。
独自の処理コンテナを構築する (高度なシナリオ) - Amazon SageMaker
ProcessingInput と ProcessingOutput の両方で、処理コンテナ内のパスは /opt/ml/processing/ から始まる必要があります。
学習データの分割・Feature Hashingを、それぞれscikit-learnの train_test_split・FeatureHasherを用いて実装します。
gistcf8b9c8c9d5d9c04f72d12670f4c1cc8
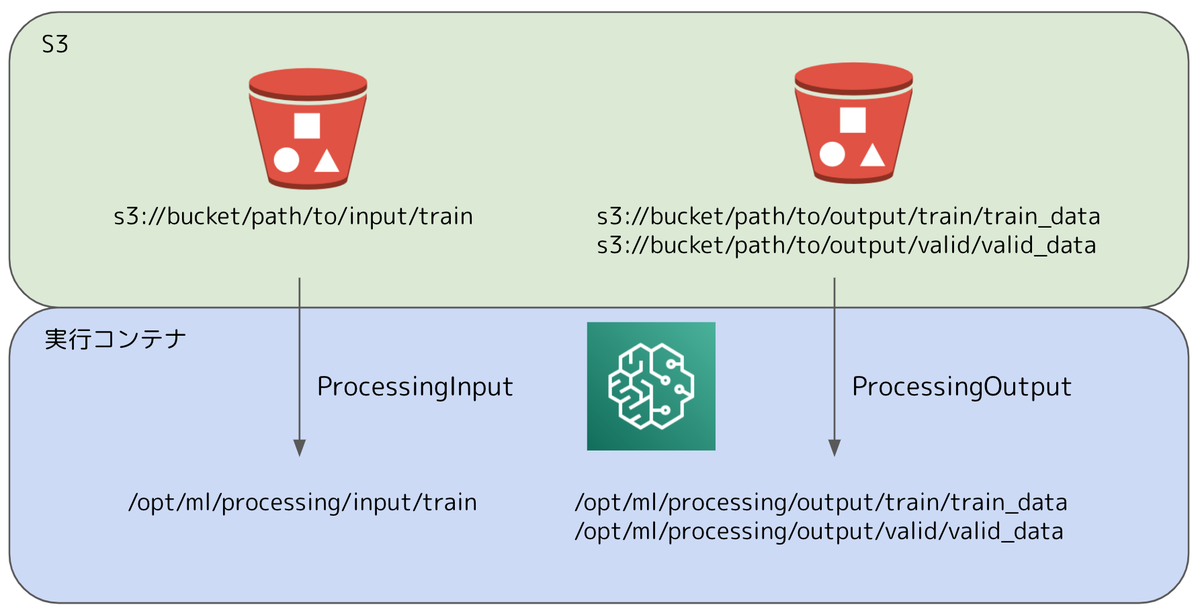
入出力データパスの対応
上述の通り、実行コンテナ内のパスと、S3のパスを対応させる必要があります。
Sagemaker Processing job の実行時に、以下のクラスを使用することで対応を行います
- ProcessingInput: 入力データ
- source: 入力データのS3(or ローカル)パス
- destination: 入力データのコンテナパス
- ProcessingOutput: 出力データ
- source: 出力データのコンテナパス
- destination: 出力データのS3パス
Processing — sagemaker 2.99.0 documentation
図で表すと、以下のようにS3のパスと、実行コンテナのパスの対応を行います。
Sagamaker Processing を実行
SKLearnProcessor クラスに使用したいscikit-learnのバージョン、インスタンスサイズ・台数を指定します。 公式Document: Scikit Learn — sagemaker 2.99.0 documentation
この時、以下の引数を指定する必要があります. code, inputs, outputs 引数に値を入れるようにしましょう。
- code: 処理スクリプトのローカル・S3 パス
- inputs: 入力データの対応
- outputs: 出力データの対応
- (arguments): 処理スクリプトの実行引数, List[str]形式で記述する
- (wait): job が完了するまで呼び出し完了するかどうか
- (logs): job実行中に生成されたログを表示するかどうか
- (job_name): job の名前
- (experiment_config): 実験管理APIのSagemaker Experimentの設定
gistd789542d42a6b980f290fcfcf1d38b97
管理画面の処理ジョブを見ると、Jobが登録されていることがわかります。

実行が完了すると、S3に加工データが保存され、インスタンスが自動で終了します。
boto3 のsagemaker client を利用してProcessing Jobの一覧を取得して、実行jobを確認することもできます
sm = boto3.client('sagemaker') jobs = sm.list_processing_jobs() pd.DataFrame(jobs['ProcessingJobSummaries'])[:1]
また、processorオブジェクトから実行jobの詳細を以下のように確認することができます
processor_description = processor.jobs[-1].describe()
processor_description
カスタムコンテナを使用する手順
カスタムコンテナを利用する場合、処理スクリプトの実装に加え、実行する docker image を作成する必要があります
- 処理に使用するデータをS3 (or ローカル)に保存
- 処理スクリプトを実装
- 実行する docker image をECRへ保存
- 生成データの保存先S3 pathを取得
- 実行 docker image を指定
自前の処理スクリプトを実装
今回はFeature Hasing とデータ分割を scikit-learn を使用せず、自前実装した関数を使用したいと思います。
gist2fd8700e79c7d41e269976ed0b584134
docker image の用意
処理スクリプトを実行するための環境を整えた docker image を作成します。
今回は独自のライブラリ等のインストールなどはありませんが、柔軟に実行環境を構築できます。
以下のDockerfileを用意します。
gistbfe27b163f0122e3db962db4e4b1f5a9
ECR にimageをpushします. Docker イメージをプッシュする - Amazon ECR
以下は jupyter notebook からDocker build して ECRへpushするコマンドです。
account_id = boto3.client('sts').get_caller_identity().get('Account') ecr_repository = f'ctr-preprocessor-custom:latest' image_uri = f'{account_id}.dkr.ecr.{region}.amazonaws.com/{ecr_repository}' !docker build . -t $image_uri !aws ecr get-login-password --region $region | docker login --username AWS --password-stdin $account_id.dkr.ecr.$region.amazonaws.com !aws ecr create-repository --repository-name $ecr_repository !docker build -t {ecr_repository} . !docker tag {ecr_repository} $image_uri !docker push $image_uri
ECRにimage がpushされていることを確認できました
Sagemaker Proessingを実行
入出力データのS3パスとコンテナパスの対応はSKLearnProcessorと同様です。Processor, ScriptProcessorを使用する場合、docker imageのuriを指定する必要があります。
Processing — sagemaker 2.99.0 documentation
今回は先ほどECRへpush したctr-prediction-custom のuriを指定します。
runメソッドで Processing Jobを実行することができます。
実行引数などはSKLearnProcessor と共通なので、同じ値で大丈夫です。
giste4f9f586508936fa71c7646ba9b554e8
Processing Jobが実行されていることが確認できます。

ScriptProcessor と Processor の違い
カスタムコンテナを利用する際にScriptProcessorとProcessor が利用できますが、両者の違いは処理スクリプトをコンテナ内に含めるかどうかにあります。
- Processor: runメソッドにcode引数(pythonスクリプト)をとらないクラスで、コンテナの作成と実行したい処理をDocker image内に記述して利用する
- ScriptProcessor: コンテナの作成と処理コードを分けて実行するクラスで、あらかじめコンテナを用意し、SKLearnProcessorとPySparkProcessorと同じようにrunメソッドにpythonスクリプトを受け渡し、処理を実行する
参考: RAPIDSをAmazon SageMaker Processingで実行する | Amazon Web Services ブログ
下記のIssueでも議論されているように、ScriptProcessorは code を引数にとり、外部から処理スクリプトを指定して実行しますが、Processor は code 引数をとりません。
Difference between ScriptProcessor vs Processor · Issue #1569 · aws/sagemaker-python-sdk · GitHub
Processor, ScriptProcessorどちらを使うかは、処理スクリプトをコンテナ内に含めるか次第なので、使用状況に合わせて選択してください。
まとめ
Sagamaker Processing をSKlearnProcessor, ScriptProcessorを用いて実行する手順を説明しました。
Sagemaker Processing はS3からの入出力の受け渡しを行う処理を行ってくれるので、MLの特徴量生成やモデル評価に限られず幅広い使用用途が可能となっています。
処理スクリプトとデータのS3パスさえ指定すれば簡単に実行できるのが魅力です。
日本語でSagemaker Processingのsampleコードを公開してくれています。
参考
- RAPIDSをAmazon SageMaker Processingで実行する | Amazon Web Services ブログ
- 独自の処理コンテナを構築する (高度なシナリオ) - Amazon SageMaker
- Amazon SageMaker Processing – フルマネージドなデータ加工とモデル評価 | Amazon Web Services ブログ
- 機械学習プロジェクトにおけるSageMaker Processingの使い所 - コネヒト開発者ブログ
- SageMaker Processingで独自アルゴリズムを使う|Dentsu Digital Tech Blog|note